set.seed(123)source("Baseline/utils.R")################ Packages ################library(plyr)# Used for mapping valuessuppressPackageStartupMessages(library(tidyverse))# ggplot2, dplyr, and magrittrlibrary(readxl)# Read in Excel fileslibrary(lubridate)# Handle dateslibrary(datefixR)# Standardise dateslibrary(patchwork)# Arrange ggplots# Generate tablessuppressPackageStartupMessages(library(table1))library(knitr)library(pander)# Generate flowchart of cohort derivationlibrary(DiagrammeR)library(DiagrammeRsvg)# paths to PREdiCCt dataif(file.exists("/docker")){# If running in dockerdata.path<-"data/final/20221004/"redcap.path<-"data/final/20231030/"upf.path<-"data/final/20240924/"prefix<-"data/end-of-follow-up/"outdir<-"data/processed/"}else{# Run on OS directlydata.path<-"/Volumes/igmm/cvallejo-predicct/predicct/final/20221004/"redcap.path<-"/Volumes/igmm/cvallejo-predicct/predicct/final/20231030/"upf.path<-"/Volumes/igmm/cvallejo-predicct/predicct/final/20240924/"prefix<-"/Volumes/igmm/cvallejo-predicct/predicct/end-of-follow-up/"outdir<-"/Volumes/igmm/cvallejo-predicct/predicct/processed/"}demo<-readRDS(paste0(outdir, "demo-biochem.RDS"))FFQ<-read_xlsx(paste0(prefix,"predicct ffq_nutrientfood groupDQI all foods_data (n1092)Nov2022.xlsx"))FFQ$meat_overall<-rowSums(FFQ[, paste0("meat7", letters[1:12], "_grams")])FFQ$fish_overall<-rowSums(FFQ[, paste0("fish8", letters[1:13], "_grams")])FFQ$ParticipantNo<-FFQ$participantnodemo<-merge(demo,FFQ[, c("ParticipantNo","Meat_sum","meat_overall","fish_overall","fibre","PUFA_percEng","NOVAScore_cat","dqi_tot")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)cat_theme<-function(gg){p<-gg+scale_fill_manual(values =c("#DA4167", "#F4D35E", "#083D77"))+scale_color_manual(values =colorspace::darken(c("#DA4167","#F4D35E","#083D77"),0.2))+theme_minimal()p}
Whilst data for many dietary variables have been collected, this report will focus on the data outlined in the SAP.
Protein from animal-sources
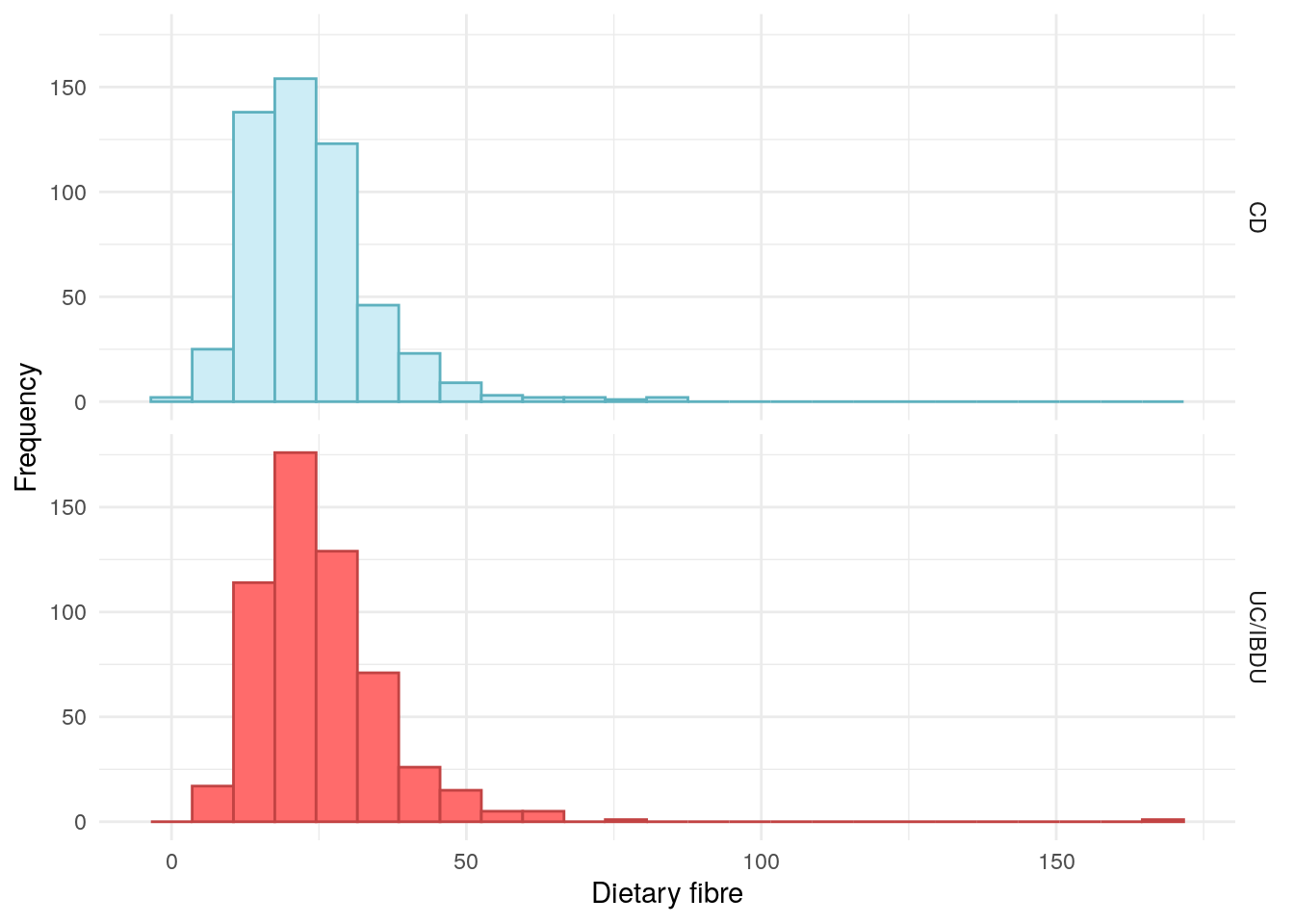
Dietary fibre
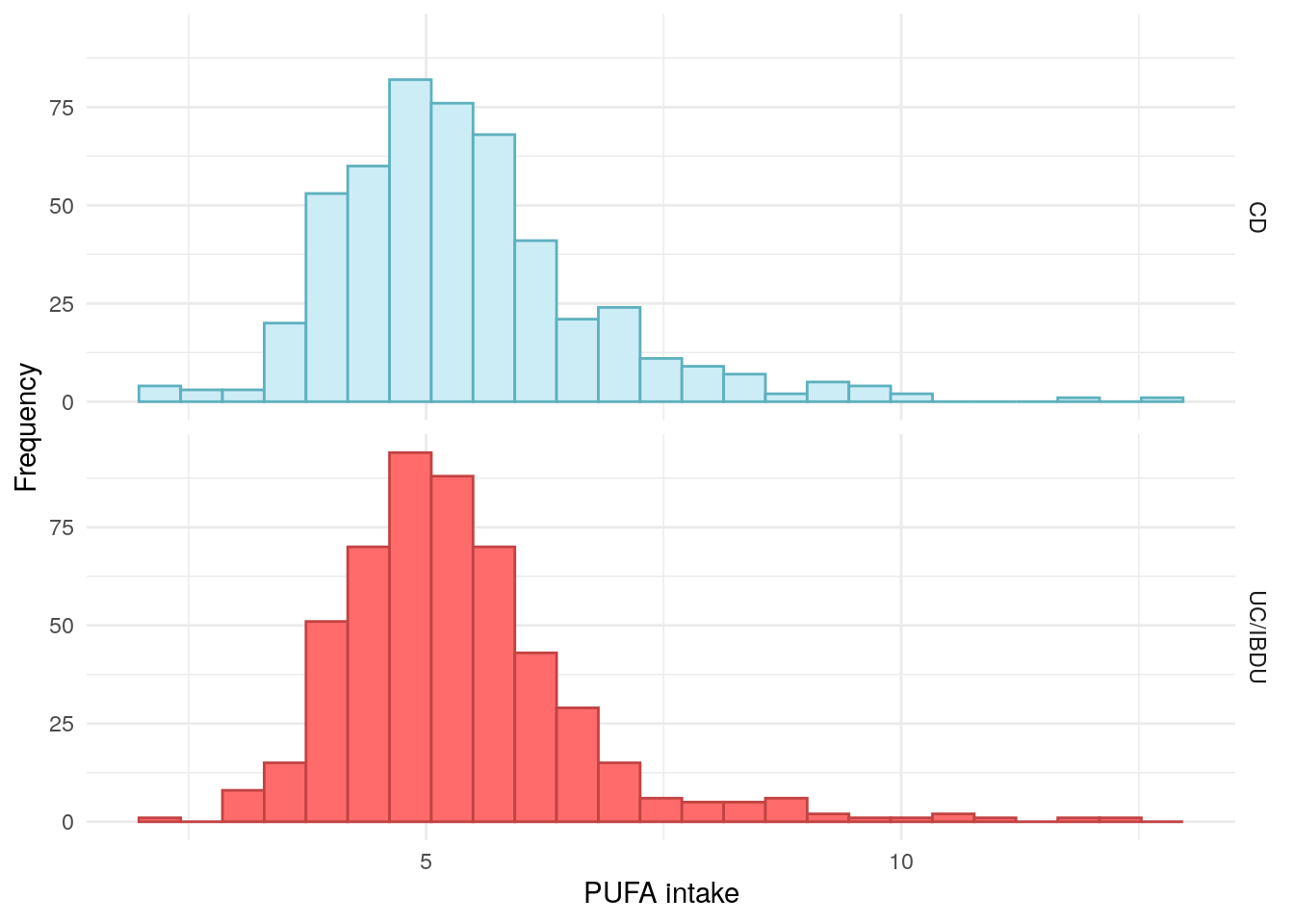
Polyunsaturated fatty acids (PUFAs)
Nova intake score
The data for these variables were extracted from the FFQs. As reported associations between dietary data and IBD are often specific to a form of IBD rather than IBD as a whole, these data will be presented stratified by disease type.
Protein from meat sources
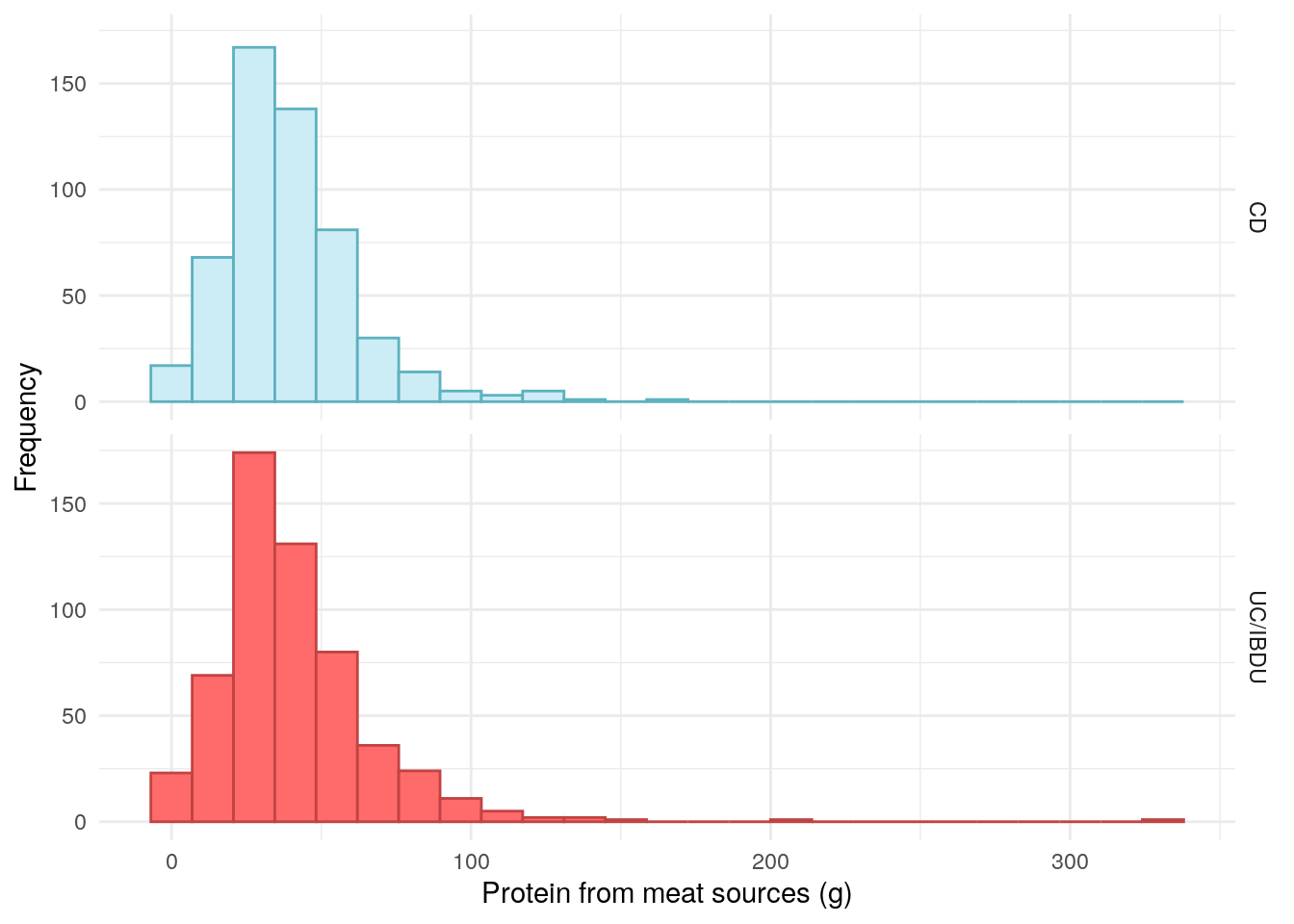
Figure 1 suggests there are relatively few vegetarians in the PREdiCCt cohort. Whilst some extreme values were observed for protein from meat sources, they remain plausible.
Code
demo%>%drop_na(Meat_sum)%>%ggplot(aes(x =Meat_sum, color =diagnosis2, fill =diagnosis2))+geom_histogram(bins =25)+theme_minimal()+theme(legend.position ="none")+labs( x ="Protein from meat sources (g)", y ="Frequency", color ="IBD type", fill ="IBD type")+scale_fill_manual( labels =c("UC/IBDU", "Crohn's"), values =c("#CDEDF6", "#FF6B6B"))+scale_color_manual( labels =c("UC/IBDU", "Crohn's"), values =c("#5EB1BF", "#C24343"))+facet_grid(rows =vars(diagnosis2))
Figure 1: Distribution of protein intake from meat.
No association was observed between protein intake from meat and FC in either CD or UC.
Table 2: ANOVA between protein intake from meat and FC groups in UC/IBDU.
Analysis of Variance Model
Df
Sum Sq
Mean Sq
F value
Pr(>F)
cat
2
3350
1675
2.814
0.06088
Residuals
512
304730
595.2
NA
NA
Overall meat intake
Code
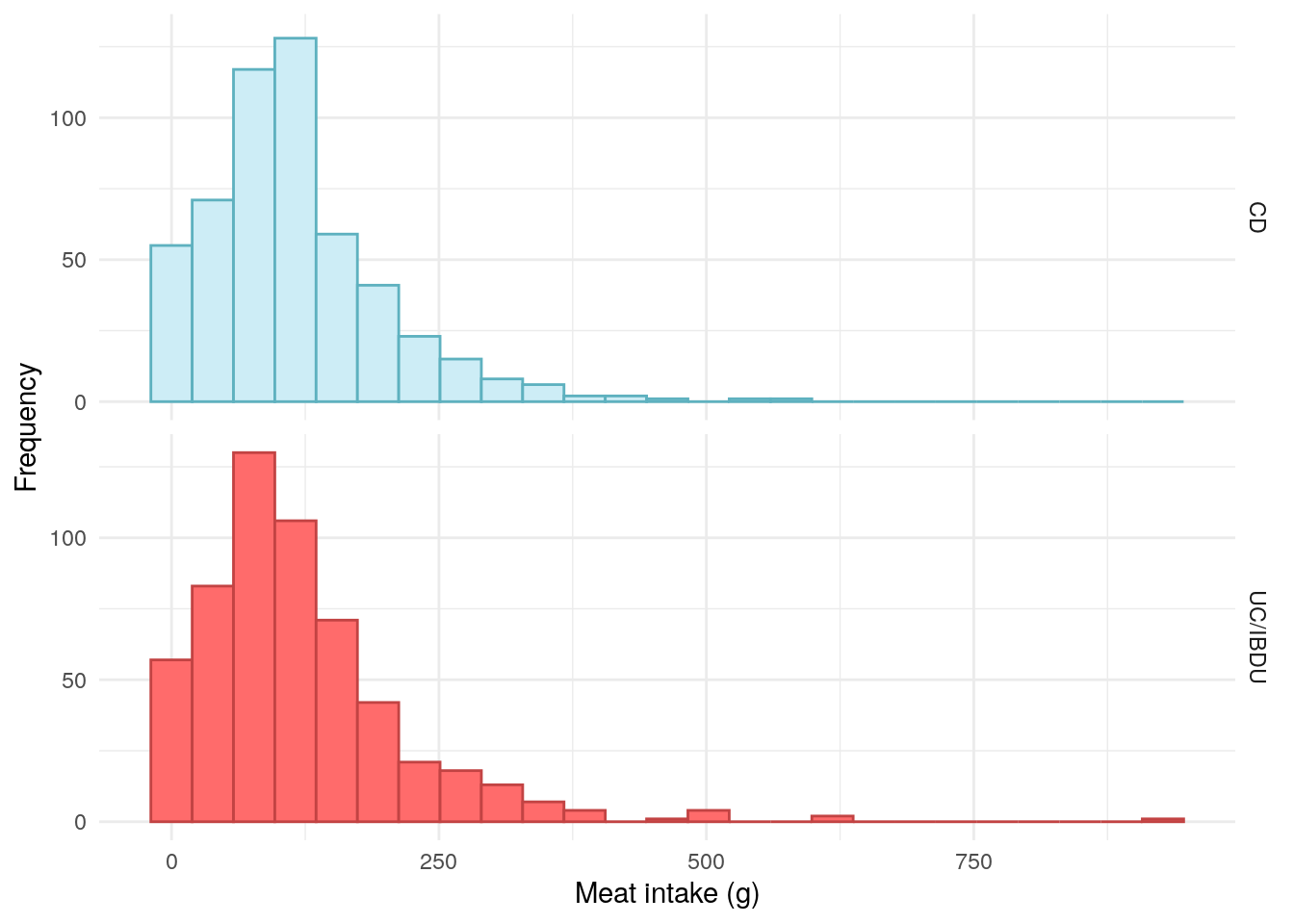
demo%>%drop_na(meat_overall)%>%ggplot(aes(x =meat_overall, color =diagnosis2, fill =diagnosis2))+geom_histogram(bins =25)+theme_minimal()+theme(legend.position ="none")+labs( x ="Meat intake (g)", y ="Frequency", color ="IBD type", fill ="IBD type")+scale_fill_manual( labels =c("UC/IBDU", "Crohn's"), values =c("#CDEDF6", "#FF6B6B"))+scale_color_manual( labels =c("UC/IBDU", "Crohn's"), values =c("#5EB1BF", "#C24343"))+facet_grid(rows =vars(diagnosis2))
Figure 2: Distribution of overall meat intake.
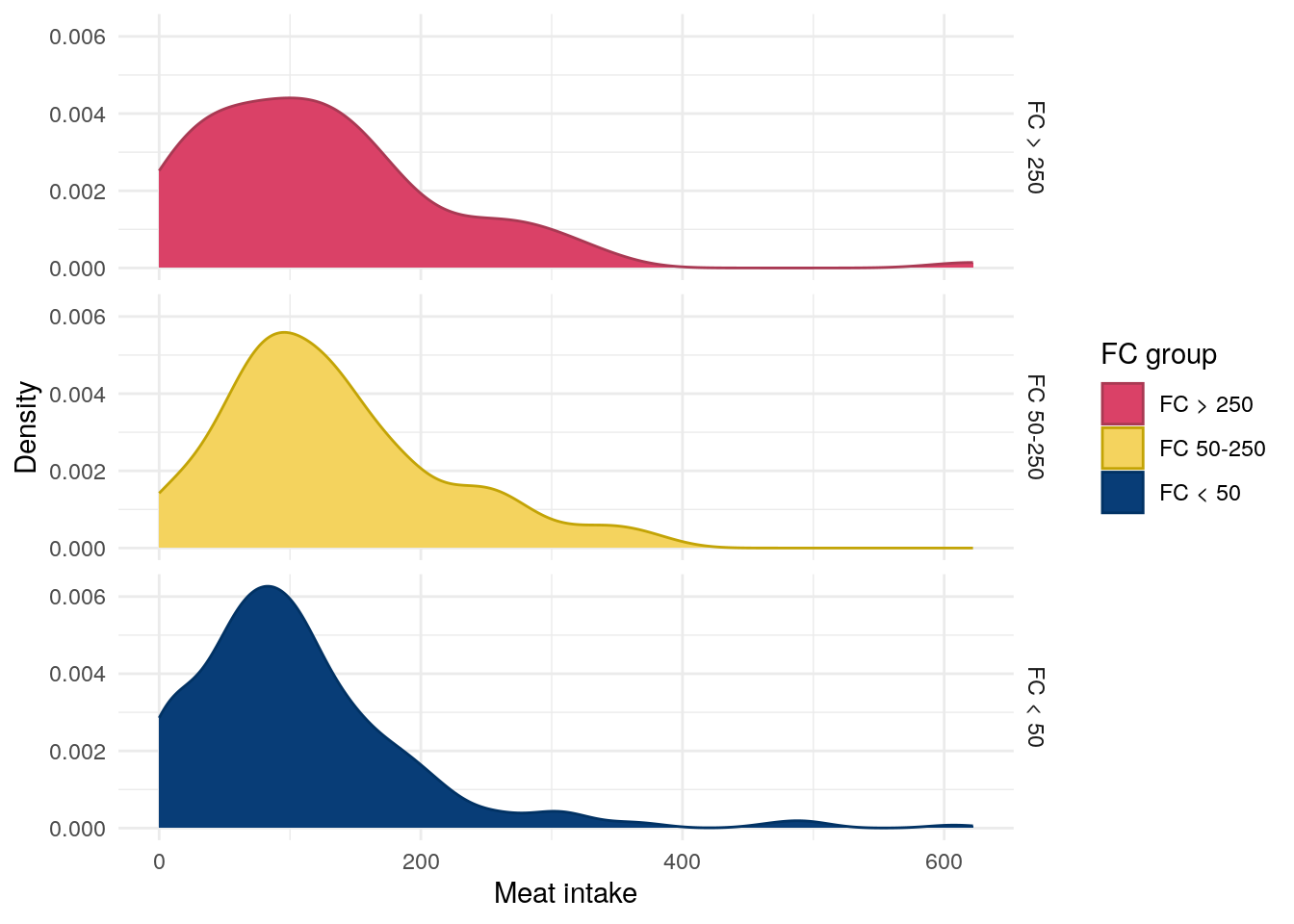
No association was observed between meat intake and FC in CD. However, a significant association was observed between meat intake and FC in UC/IBDU Table 4.
Figure 3: Distribution of meat intake by FC in UC.
Overall fish intake
Code
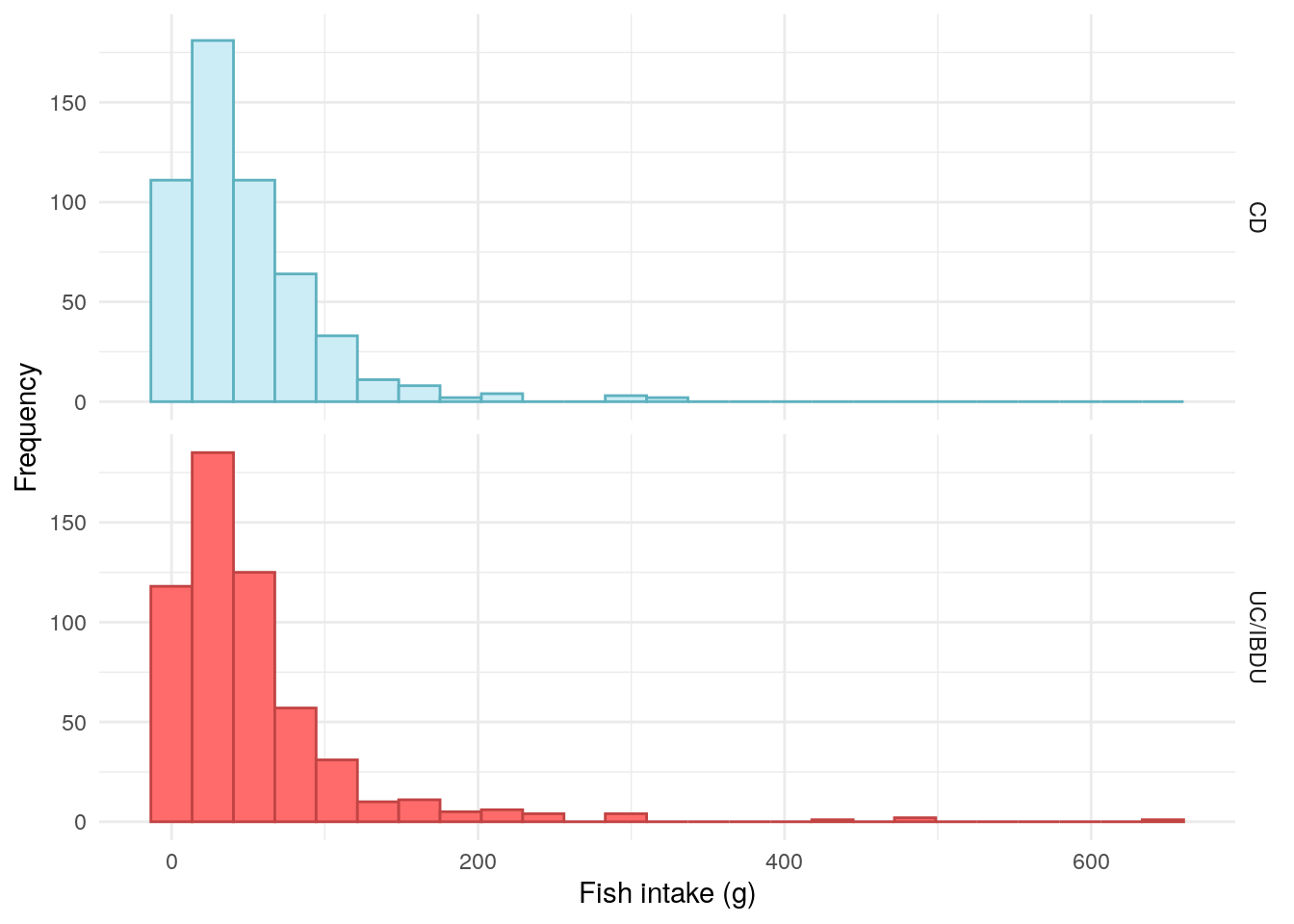
demo%>%drop_na(fish_overall)%>%ggplot(aes(x =fish_overall, color =diagnosis2, fill =diagnosis2))+geom_histogram(bins =25)+theme_minimal()+theme(legend.position ="none")+labs( x ="Fish intake (g)", y ="Frequency", color ="IBD type", fill ="IBD type")+scale_fill_manual( labels =c("UC/IBDU", "Crohn's"), values =c("#CDEDF6", "#FF6B6B"))+scale_color_manual( labels =c("UC/IBDU", "Crohn's"), values =c("#5EB1BF", "#C24343"))+facet_grid(rows =vars(diagnosis2))
Figure 4: Distribution of overall fish intake.
No association was observed between meat intake and FC in CD. However, a significant association was observed between meat intake and FC in UC/IBDU Table 4.
Table 6: ANOVA between fish intake and FC groups in UC/IBDU.
Analysis of Variance Model
Df
Sum Sq
Mean Sq
F value
Pr(>F)
cat
2
1986
992.9
0.2838
0.753
Residuals
512
1791051
3498
NA
NA
Dietary fibre
Fibre has frequently investigated as a potential factor in IBD pathogenesis, particularly in CD.
A study of 170,776 women across 26 years found fibre intake, particularly fibre derived from fruits, to be low for incident CD patients (Ananthakrishnan et al. 2013).
A US study of 1,130 CD subjects found CD patients who reported that they did not avoid high-fibre foods were approximately 40% less likely to have a disease flare in a 6-month period than those who avoided high-fibre foods (Brotherton et al. 2016).
There is less evidence of a relationship between UC and dietary fibre.
There does not appear to be substantial differences in fibre between CD and UC/IBDU PREdiCCt participants.
Table 8: ANOVA between dietary fibre and FC groups in UC/IBDU.
Analysis of Variance Model
Df
Sum Sq
Mean Sq
F value
Pr(>F)
cat
2
80.2
40.1
0.3739
0.6882
Residuals
512
54910
107.2
NA
NA
Polyunsaturated fatty acids
PUFAs exhibit anti-inflammatory properties and there is evidence of a relationship between PUFAs and UC incidence (Marion-Letellier et al. 2013). Research suggests that a diet with a poor balance of n-3 and n-6 PUFAs, commonly seen in “Western” diets is associated with IBD risk.
The PREdiCCt SAP states n-6 PUFAs will be examined. However, the data obtained from the FFQs describes PUFAs as a whole (including n-3 PUFAs).
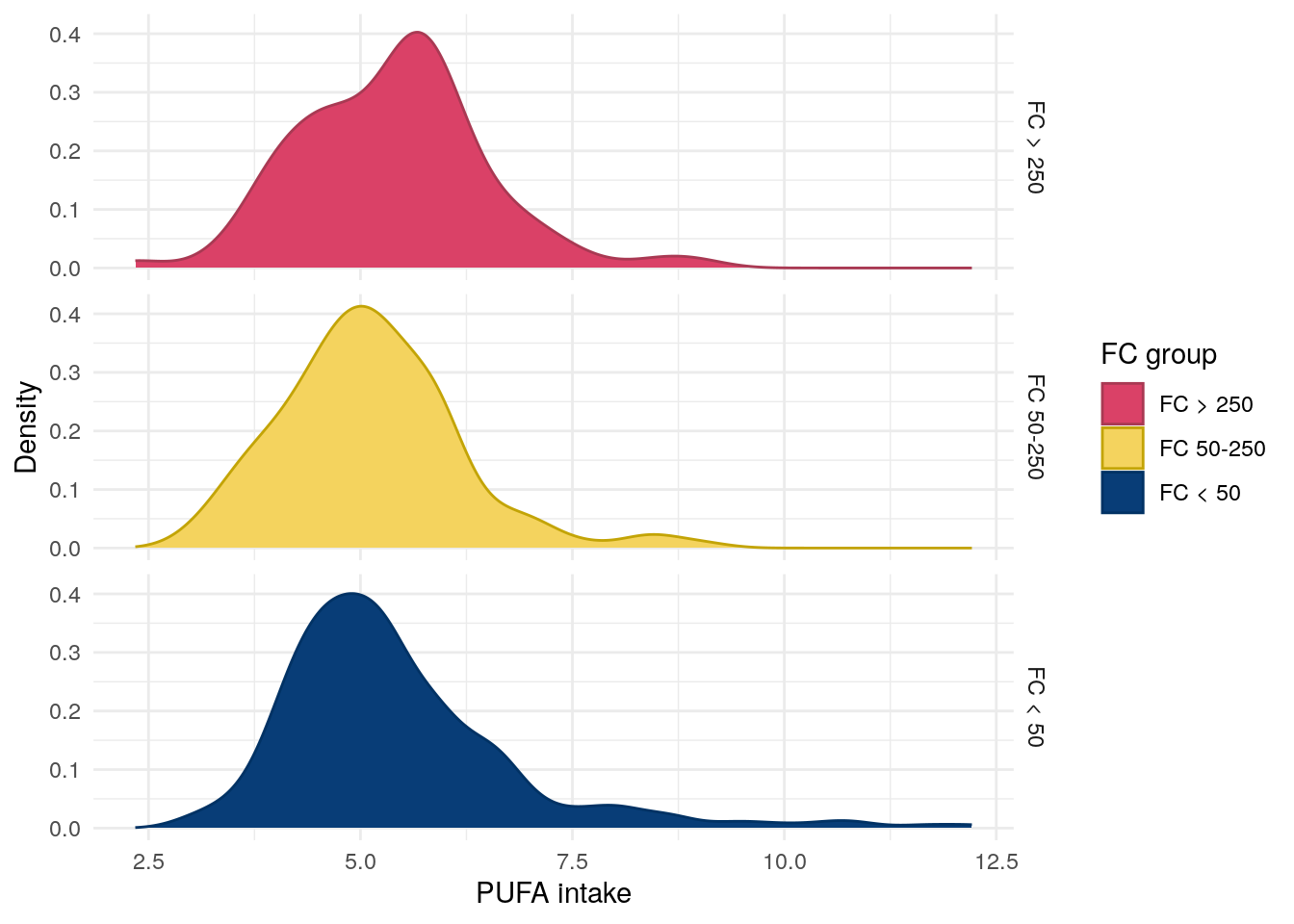
Figure 7: Distribution ofpolyunsaturated fatty acid intake by FC in UC.
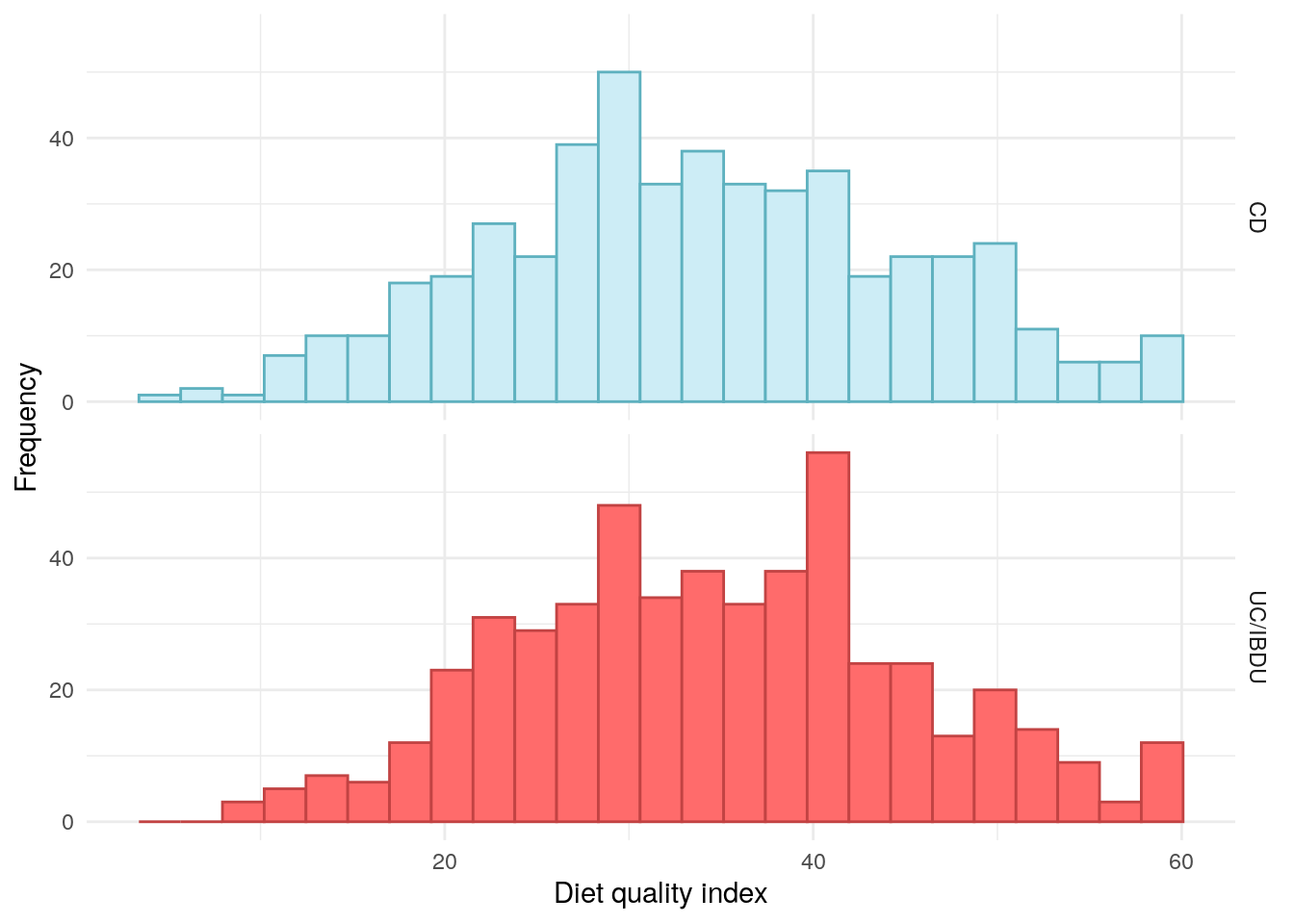
Diet qualiy index
Diet quality index (DQI) is a measure of overall diet quality ranging from 0 to 100. A higher DQI indicates a diverse diet likely meeting recommended daily intakes but reflecting moderation whilst low values indicate the converse. We used Diet Quality Index-International (DQI-I) which has been validated for use in diverse populations (Kim et al. 2003). It should be noted DQI does not necessarily relate to ultra-processed food intake.
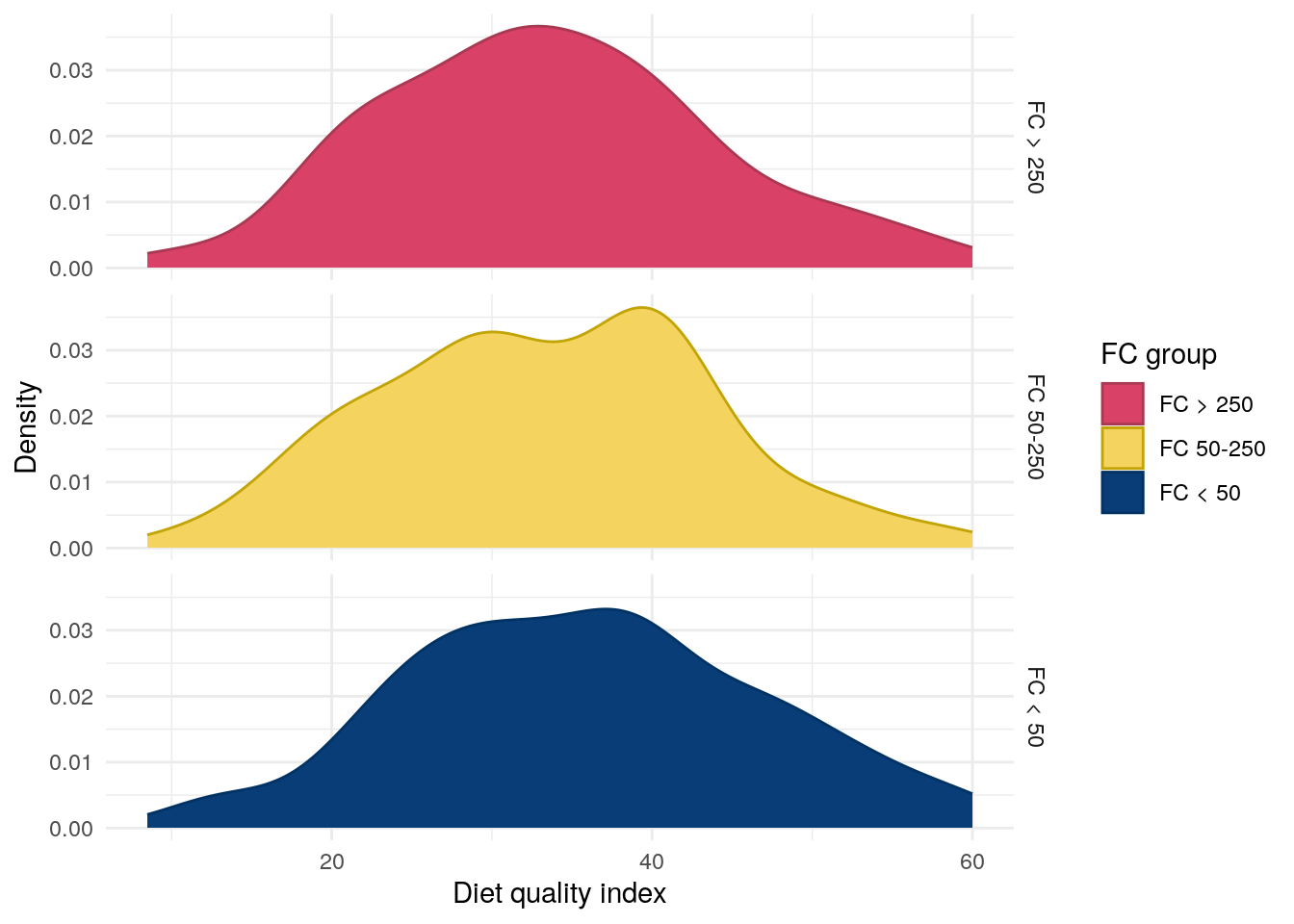
Figure 8: Distribution of diet quality index by FC in UC.
Nova intake score
There has been a great deal of recent research interest in ultra processed food (UPF) and IBD. For example, Narula et al. (2021) found UPF intake to be positively associated with IBD risk.
The Nova score is a popular approach for classifying UPFs (Monteiro et al. 2017). Food is classified as either unprocessed, processed culinary, processed food, or ultra-processed via the Nova score. The University of Aberdeen have developed an extension of the Nova score, the Nova intake score, which can be used to categorise individuals and their diets instead of individual food items.
The following definition of the Nova intake score was written by Liam McAdie during a 5th year medical elective in which he worked on the PREdiCCt dietary data. The formulae have received minor modifications, but otherwise the definitions remain unchanged from McAdie’s work.
Definition
When completing the FFQ, participants were asked to report (a) portion size normally consumed, (b) number of times this portion is consumed in one day and (c) number of days per week food type is consumed. Participant’s daily average consumption (in grams) of a food and drink type (x) was calculated by:
x=\frac{c}{7}(a+b)
Standardised number of portions consumed daily for food and drink type (y) was calculated by dividing consumption (x) by the Foods Standard Agency average UK-portion size (z).
y= \frac{x}{z}
Nova intake scores (N) were calculated by multiplying the number of standardised portions consumed (y) by their corresponding Nova score (M) assigned in the database. This process is repeated for all 169 food and drink types and totalled to give one overall Nova intake score. This score is a marker representative of UPF intake.
N = \sum_{i = 1}^{169} (y_i M_i)
Results
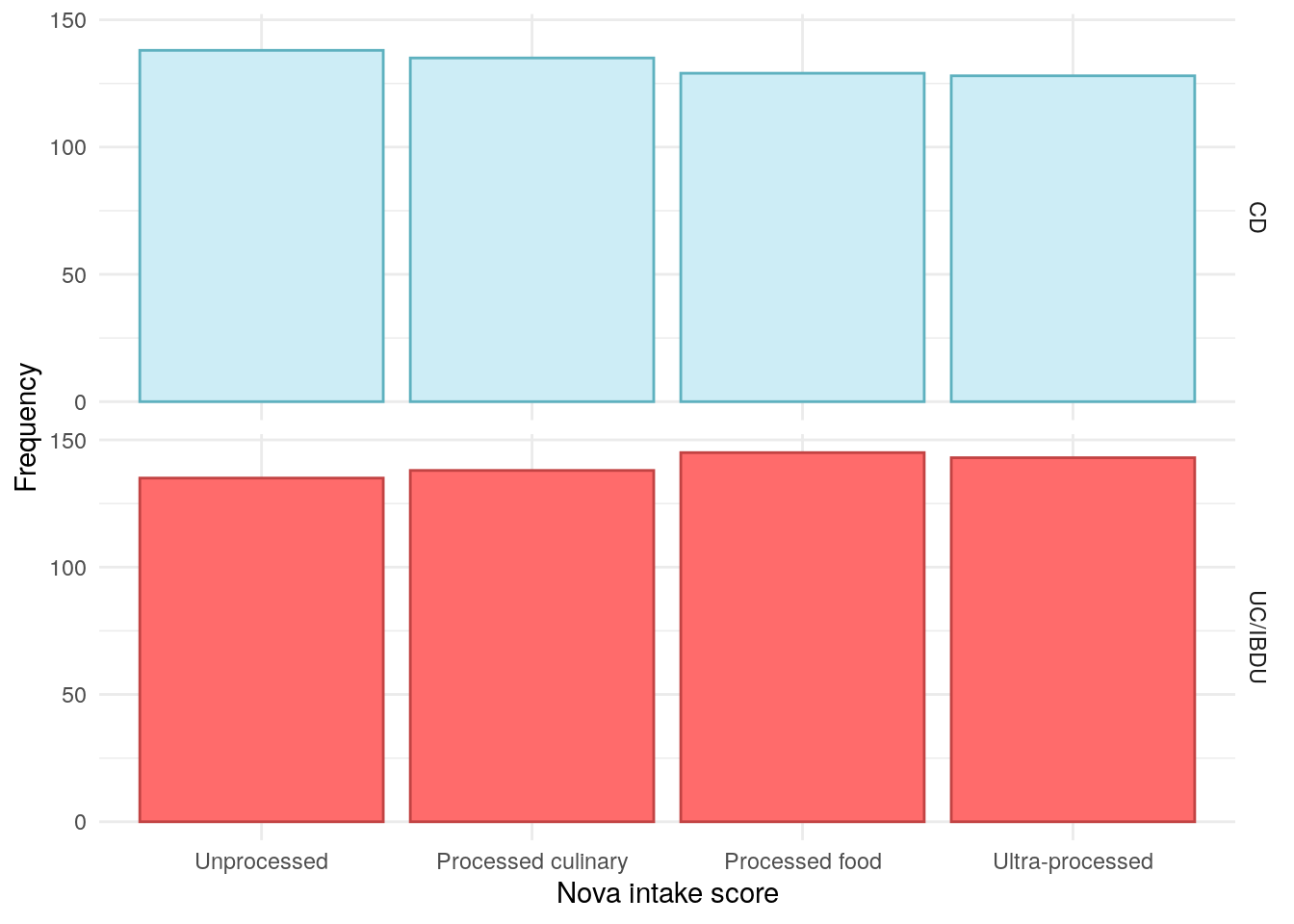
The distribution of Nova intake score appears to be uniform across the cohort, as such, it seems likely that these data have been mapped to quantiles and are no longer describing Nova Score categories.
Code
demo$NOVAScore_cat<-factor(demo$NOVAScore_cat, levels =1:4, labels =c("Unprocessed","Processed culinary","Processed food","Ultra-processed"))demo%>%drop_na(NOVAScore_cat)%>%ggplot(aes(x =NOVAScore_cat, color =diagnosis2, fill =diagnosis2))+geom_bar()+theme_minimal()+theme(legend.position ="none")+labs( x ="Nova intake score", y ="Frequency", color ="IBD type", fill ="IBD type")+scale_fill_manual( values =c("#CDEDF6", "#FF6B6B"))+scale_color_manual( values =c("#5EB1BF", "#C24343"))+facet_grid(rows =vars(diagnosis2))
Figure 9: Distribution of Nova intake scores.
No significant association was observed between Nova intake scores and FC groups.
Chi-squared test between Nova intake score and FC groups in UC/IBDU.
Test statistic
df
P value
4.197
6
0.6501
Processed food subgroups
In addition to exploring UPF intake as a whole, we also explore UPF intake by subcategories. This approach is based on the methodology used by Cordova et al. (2023). The following categories have been identified by Dr Maiara Brusco De Freitas using FFQ groupings.
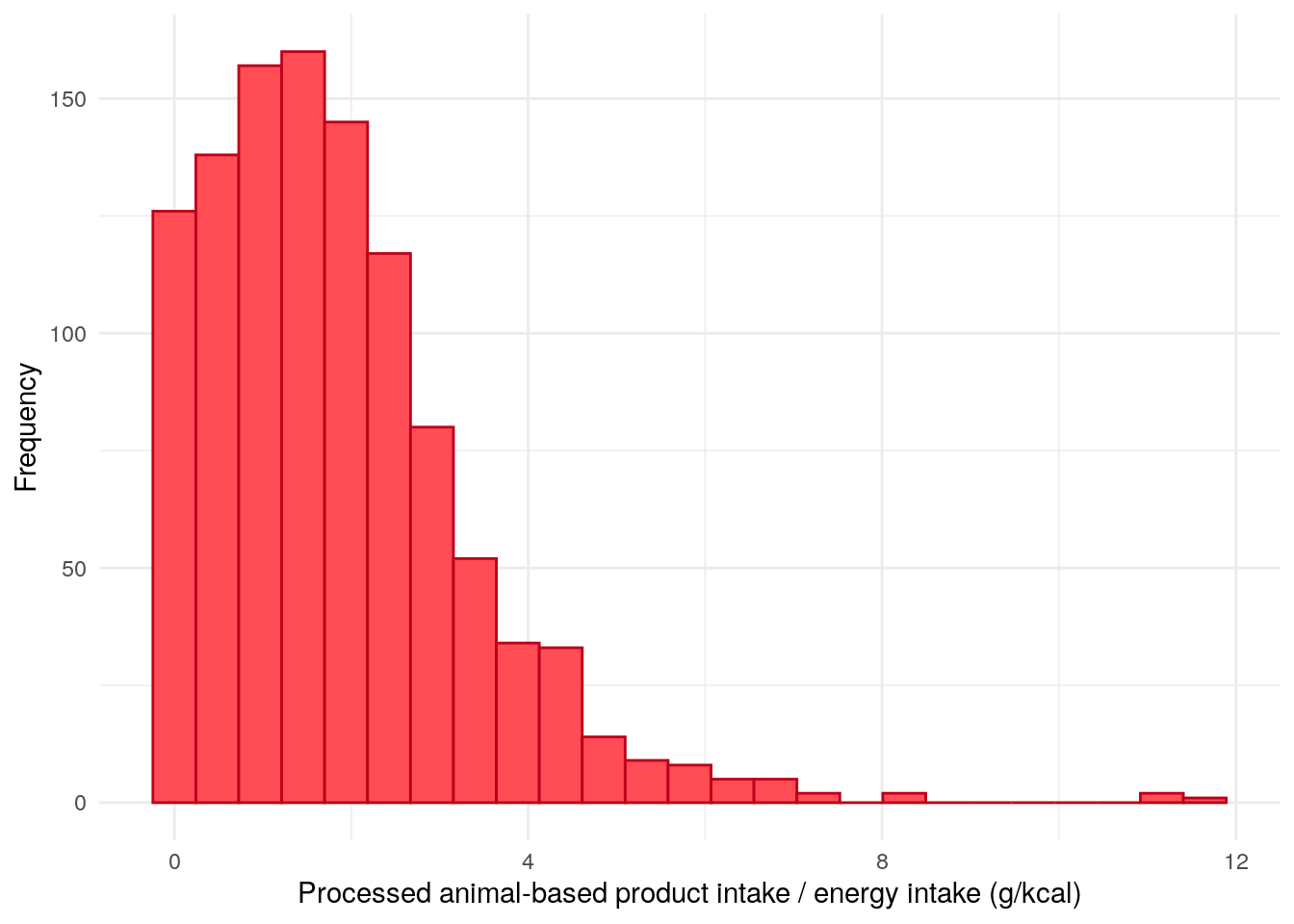
Animal-based products (processed meat) is the only subgroup considered which we found to be significantly associated with FC.
FFQ$breadIntake<-with(FFQ,(bread1a_grams+bread1b_grams+bread1c_grams+bread1d_grams+cereal2a_grams+cereal2b_grams+cereal2c_grams+cereal2d_grams+cereal2e_grams)/EnergykCAL)*100demo<-merge(demo,FFQ[, c("ParticipantNo", "breadIntake")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)demo%>%drop_na(breadIntake)%>%ggplot(aes(x =breadIntake))+geom_histogram(bins =25, color ="#5C738F", fill ="#759EB8")+theme_minimal()+xlab("Processed bread and cereal intake / energy intake (g/kcal)")+ylab("Frequency")
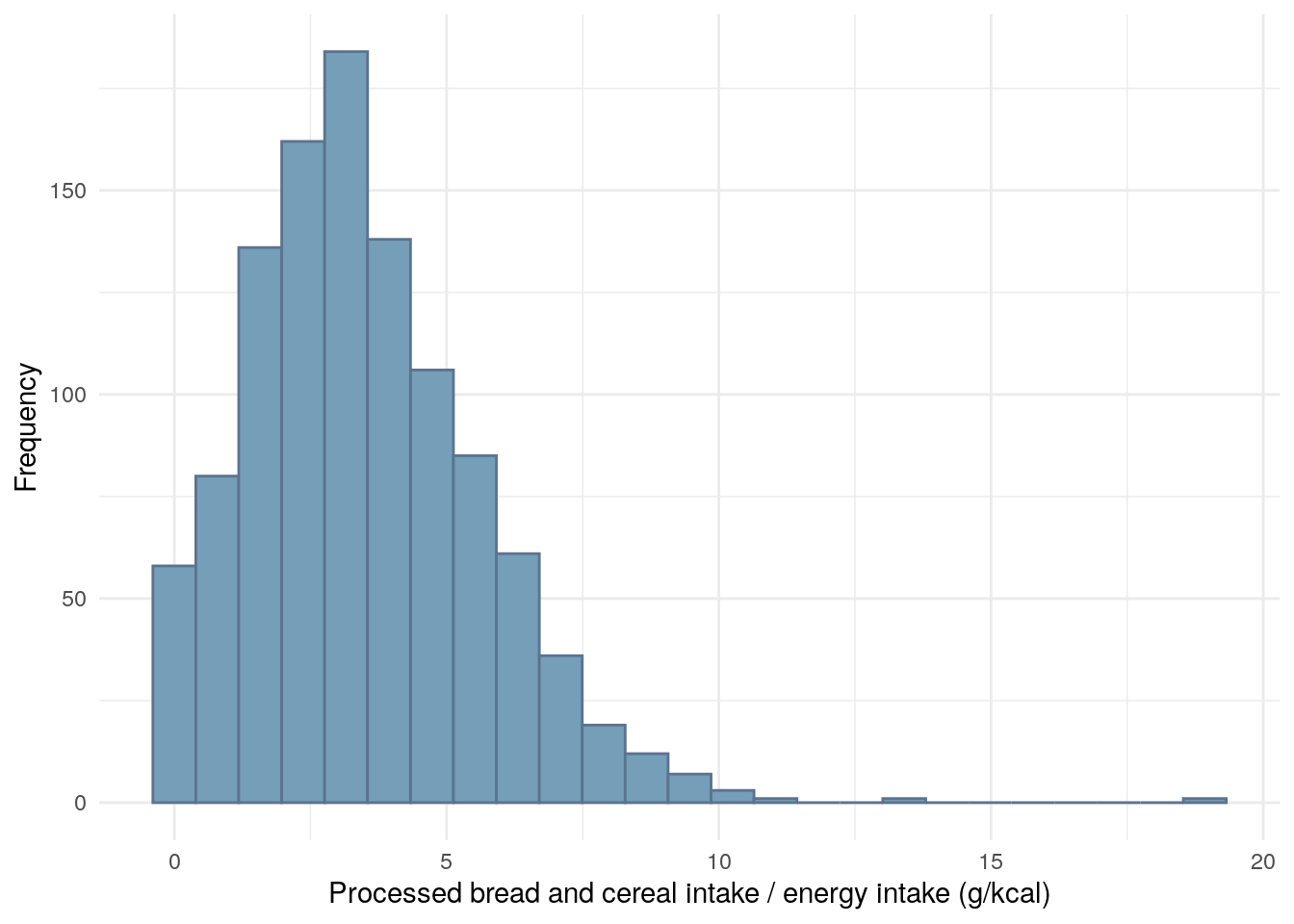
Figure 10: Distribution of processed bread and cereal intake divided by daily energy intake.
Table 13: ANOVA between processed bread/cereal intake and FC groups.
Analysis of Variance Model
Df
Sum Sq
Mean Sq
F value
Pr(>F)
cat
2
15.73
7.867
1.718
0.1799
Residuals
1009
4620
4.579
NA
NA
Code
FFQ$sweetIntake<-with(FFQ,(Puddings13a_grams+Puddings13b_grams+Puddings13c_grams+Puddings13d_grams+Puddings13e_grams+Puddings13f_grams+Puddings13g_grams+Puddings13h_grams+Chocsetc14a_grams+Chocsetc14b_grams+Chocsetc14c_grams+Chocsetc14d_grams+Chocsetc14g_grams+Chocsetc14h_grams+Chocsetc14i_grams+Biscuits15a_grams+Biscuits15b_grams+Biscuits15c_grams+Biscuits15d_grams+Biscuits15e_grams+Biscuits15g_grams+Cakes16a_grams+Cakes16b_grams+Cakes16c_grams+Cakes16d_grams+Cakes16e_grams)/EnergykCAL)*100demo<-merge(demo,FFQ[, c("ParticipantNo", "sweetIntake")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)demo%>%drop_na(sweetIntake)%>%ggplot(aes(x =sweetIntake))+geom_histogram(bins =25, color ="#B25966", fill ="#FFA3AF")+theme_minimal()+xlab("Sweet/dessert/snack intake / energy intake (g/kcal)")+ylab("Frequency")
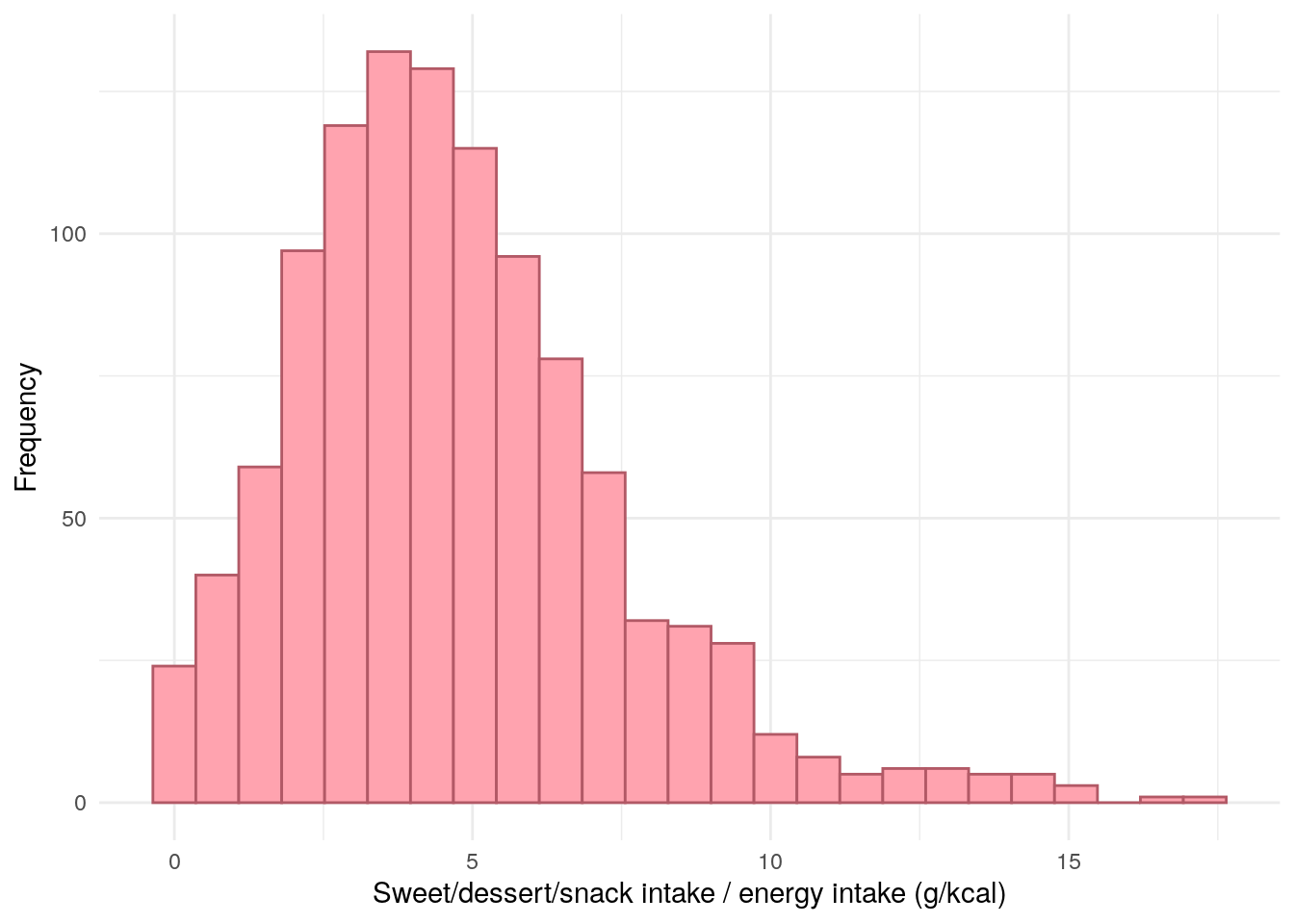
Figure 11: Distribution of Sweet and dessert/snack intake divided by daily energy intake.
Code
#| label: tbl-sweetintake-uc#| tbl-cap: "ANOVA between sweet/dessert/snack intake intake and FC for UC/IBDU."demo%>%filter(diagnosis2=="UC/IBDU")%>%aov(formula =sweetIntake~cat)%>%summary()%>%pander()
Analysis of Variance Model
Df
Sum Sq
Mean Sq
F value
Pr(>F)
cat
2
28.62
14.31
2.053
0.1294
Residuals
512
3569
6.971
NA
NA
Code
#| label: tbl-sweetIntake#| tbl-cap: "ANOVA between sweet/dessert/snack intake and FC groups."pander(summary(aov(sweetIntake~cat, data =demo)))
Analysis of Variance Model
Df
Sum Sq
Mean Sq
F value
Pr(>F)
cat
2
1.351
0.6754
0.09064
0.9134
Residuals
1009
7518
7.451
NA
NA
Code
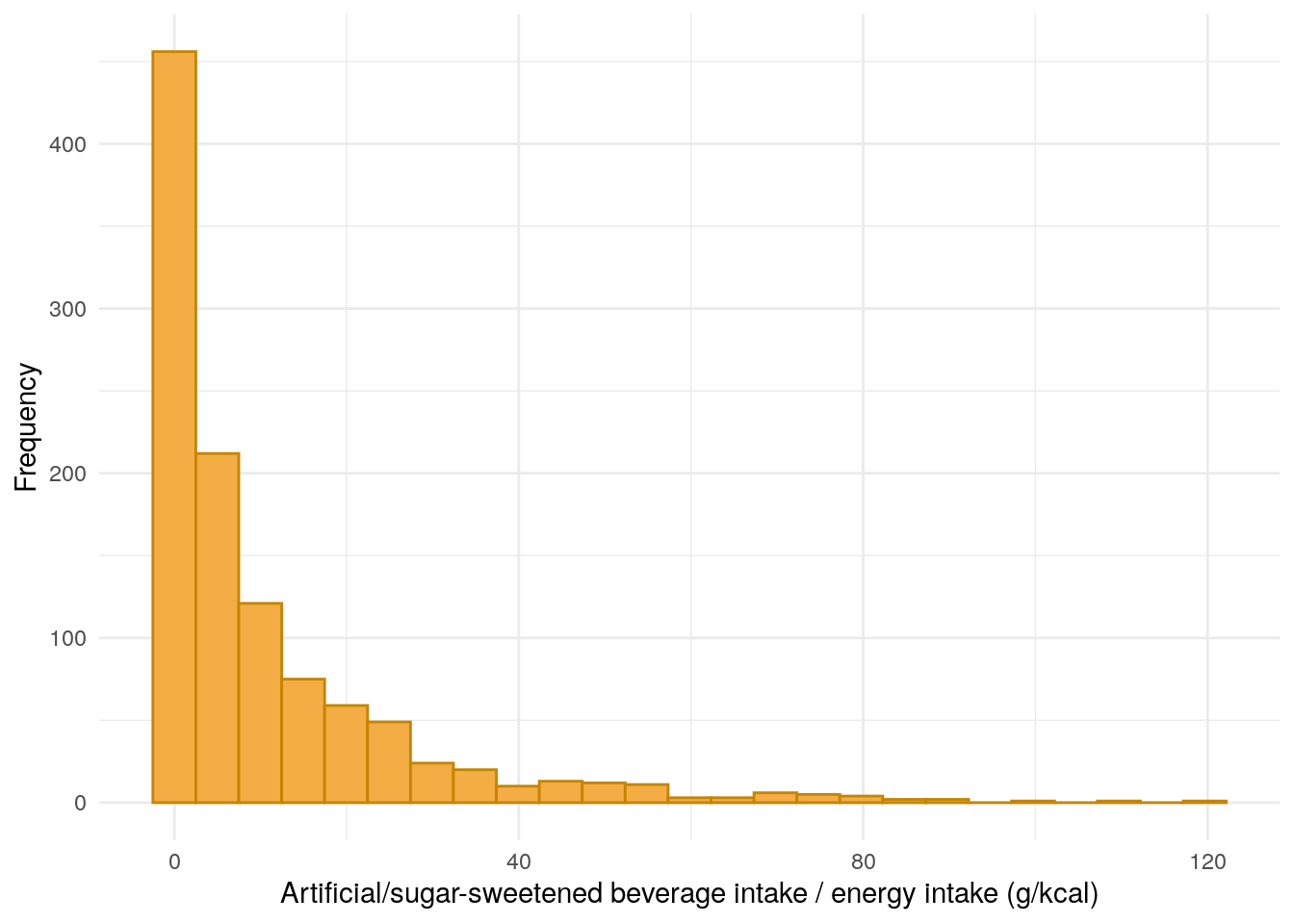
FFQ$drinkIntake<-with(FFQ,(Beverages18h_grams+Beverages18i_grams+Beverages18j_grams+Beverages18k_grams+Beverages18n_grams+Beverages18o_grams)/EnergykCAL)*100demo<-merge(demo,FFQ[, c("ParticipantNo", "drinkIntake")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)demo%>%drop_na(drinkIntake)%>%ggplot(aes(x =drinkIntake))+geom_histogram(bins =25, color ="#C58500", fill ="#F4AC45")+theme_minimal()+xlab("Artificial/sugar-sweetened beverage intake / energy intake (g/kcal)")+ylab("Frequency")
Figure 12: Distribution of artificially and sugar-sweetened drink intake divided by daily energy intake.
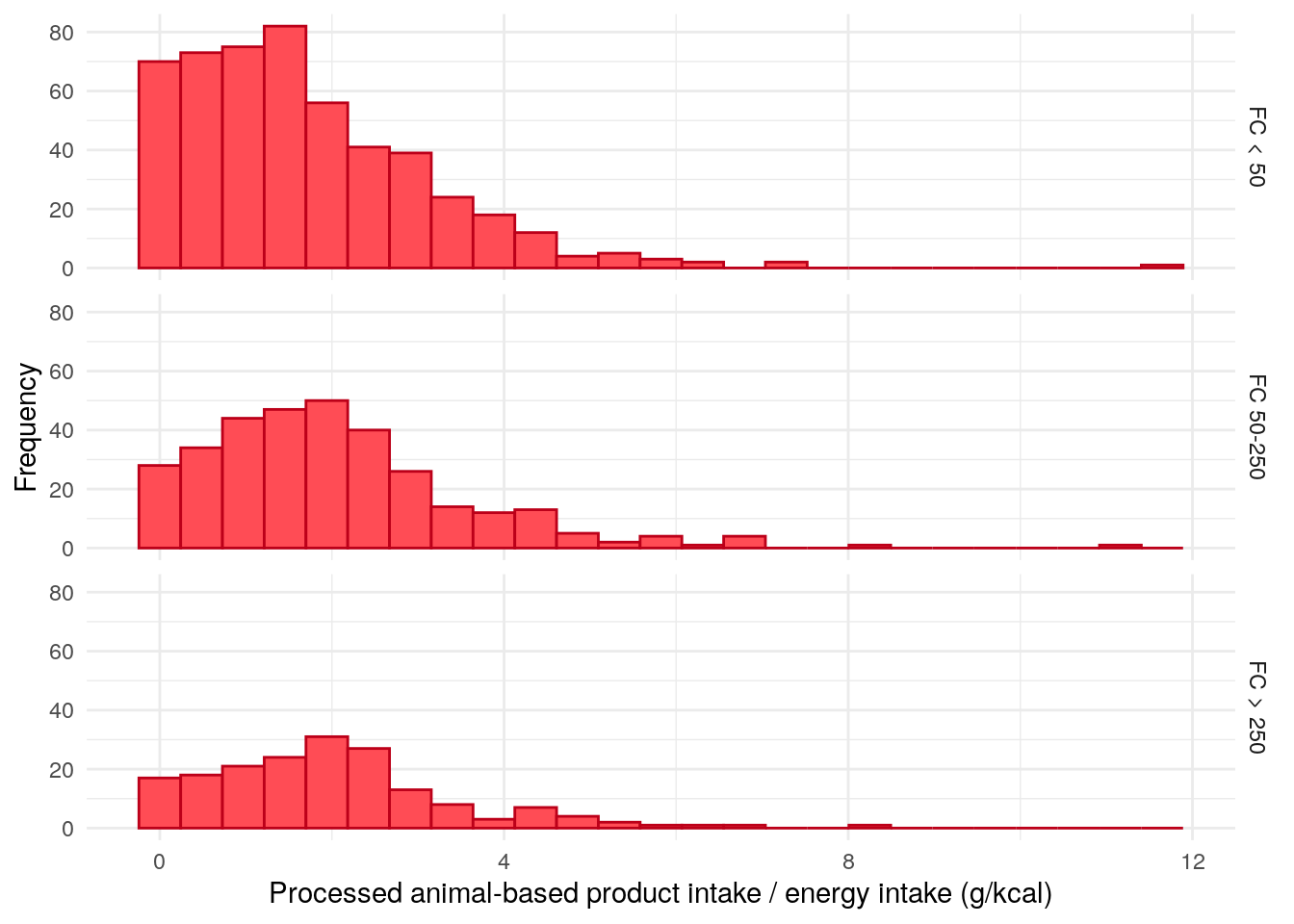
Figure 14: Distribution of processed animal-based product intake, divided by daily energy intake, and stratified by faecal calprotectin category.
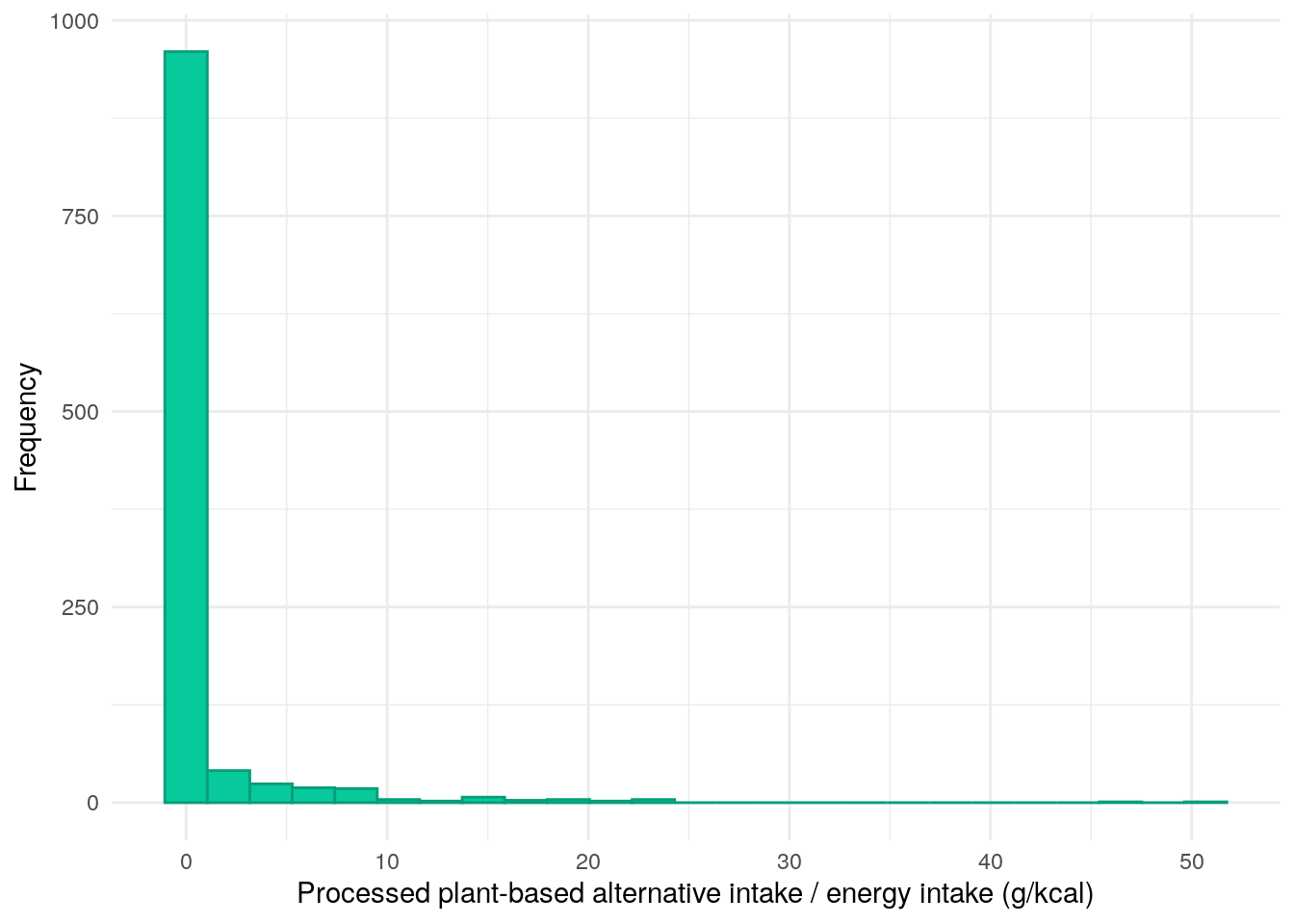
As one would likely expect, consumption of processed plant-based alternatives is low.
Code
FFQ$processedPlantIntake<-with(FFQ,(Milk3d_grams+Sav_etc10d_grams+Sav_etc10e_grams+Sav_etc10f_grams)/EnergykCAL)*100demo<-merge(demo,FFQ[, c("ParticipantNo", "processedPlantIntake")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)demo%>%drop_na(processedPlantIntake)%>%ggplot(aes(x =processedPlantIntake))+geom_histogram(bins =25, color ="#069E79", fill ="#08C99B")+theme_minimal()+xlab("Processed plant-based alternative intake / energy intake (g/kcal)")+ylab("Frequency")
Figure 15: Distribution of processed plant-based alternatives divided by daily energy intake.
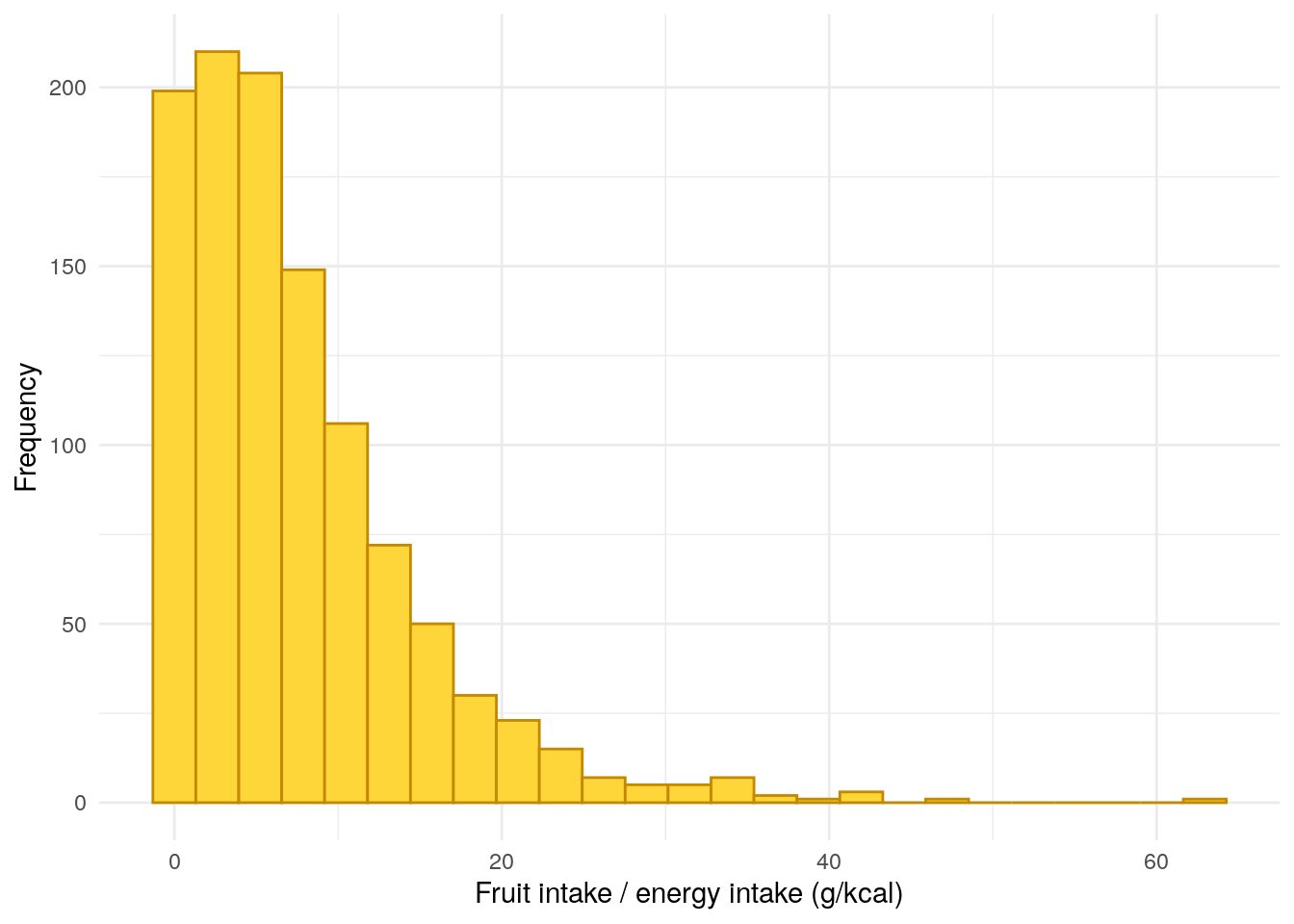
FFQ$fruitIntake<-with(FFQ,(fruit12a_grams+fruit12b_grams+fruit12c_grams+fruit12c_grams+fruit12f_grams+fruit12g_grams+fruit12h_grams+fruit12i_grams+fruit12j_grams)/EnergykCAL)*100demo<-merge(demo,FFQ[, c("ParticipantNo", "fruitIntake")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)demo%>%drop_na(fruitIntake)%>%ggplot(aes(x =fruitIntake))+geom_histogram(bins =25, color ="#C58901", fill ="#FFD639")+theme_minimal()+xlab("Fruit intake / energy intake (g/kcal)")+ylab("Frequency")
Figure 16: Distribution of fruit intake divided by daily energy intake.
Table 17: ANOVA between fruit intake and FC groups.
Analysis of Variance Model
Df
Sum Sq
Mean Sq
F value
Pr(>F)
cat
2
193.2
96.59
1.821
0.1624
Residuals
1009
53513
53.04
NA
NA
Code
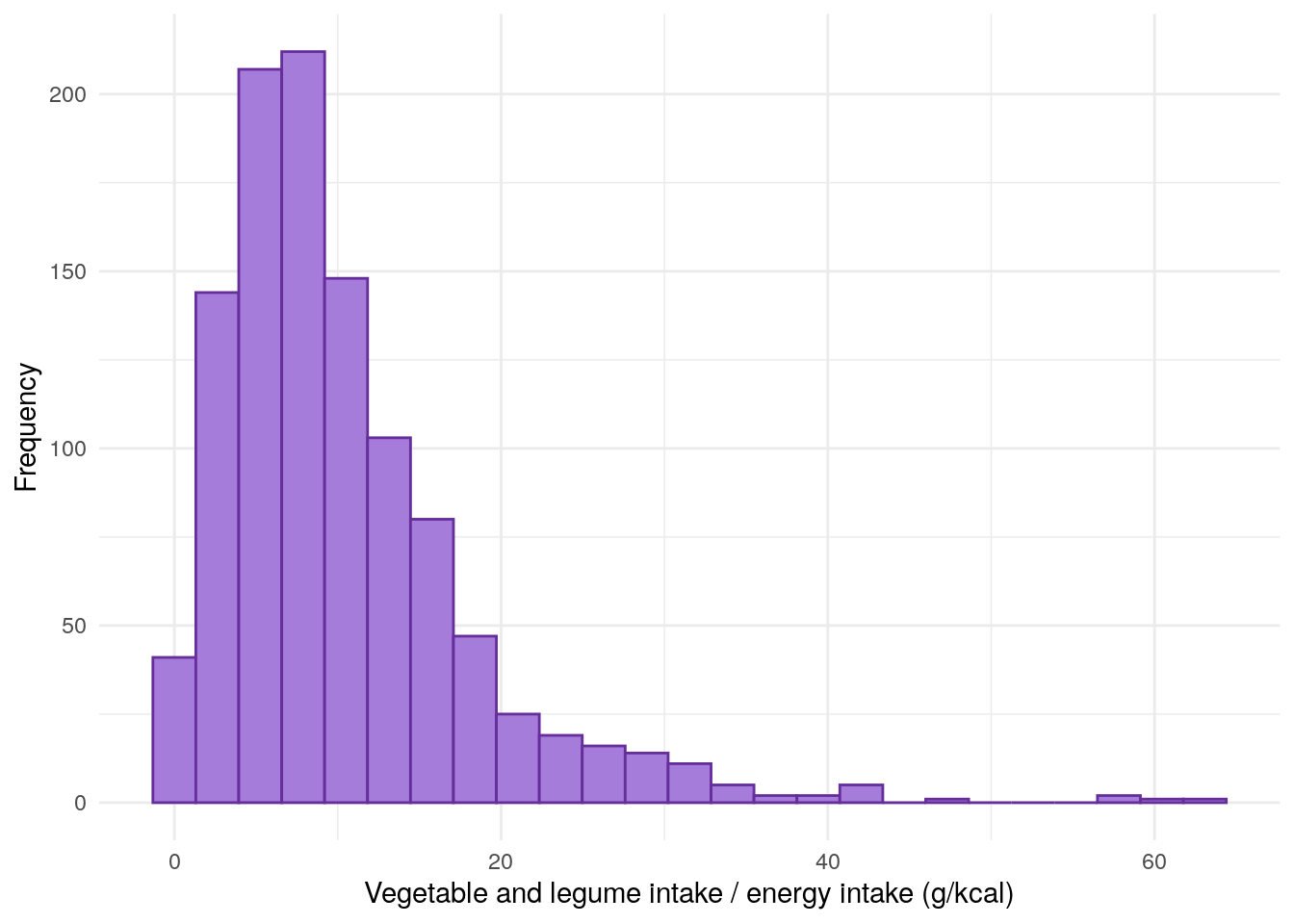
FFQ$vegIntake<-with(FFQ,(Veg11a_grams+Veg11b_grams+Veg11c_grams+Veg11d_grams+Veg11e_grams+Veg11f_grams+Veg11g_grams+Veg11h_grams+Veg11i_grams+Veg11j_grams+Veg11k_grams+Veg11l_grams+Veg11m_grams+Veg11n_grams+Veg11o_grams+Veg11p_grams+Pulses)/EnergykCAL)*100demo<-merge(demo,FFQ[, c("ParticipantNo", "vegIntake")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)demo%>%drop_na(vegIntake)%>%ggplot(aes(x =vegIntake))+geom_histogram(bins =25, color ="#662E9B", fill ="#A57CD9")+theme_minimal()+xlab("Vegetable and legume intake / energy intake (g/kcal)")+ylab("Frequency")
Figure 17: Distribution of vegetable and legume intake divided by daily energy intake.
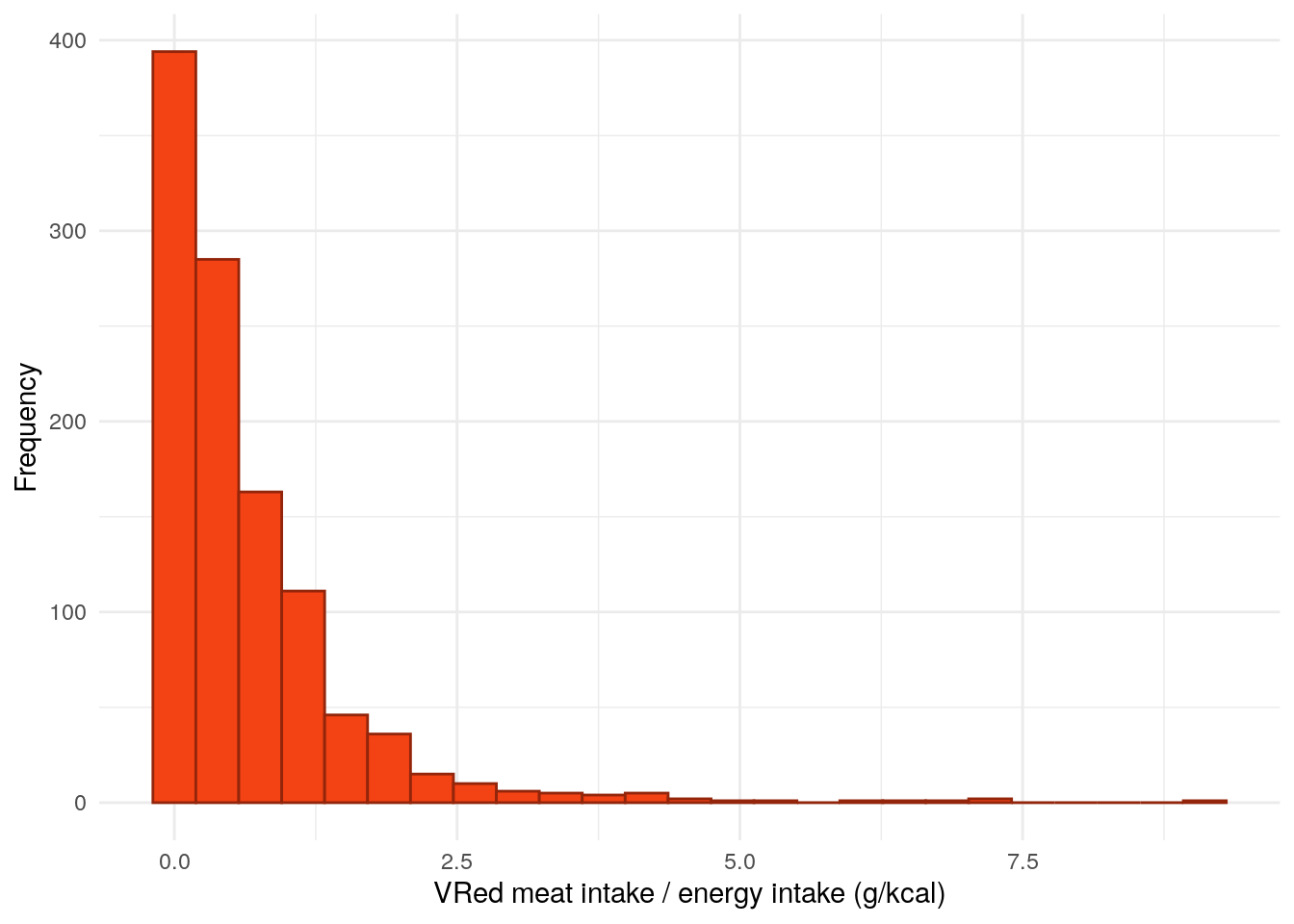
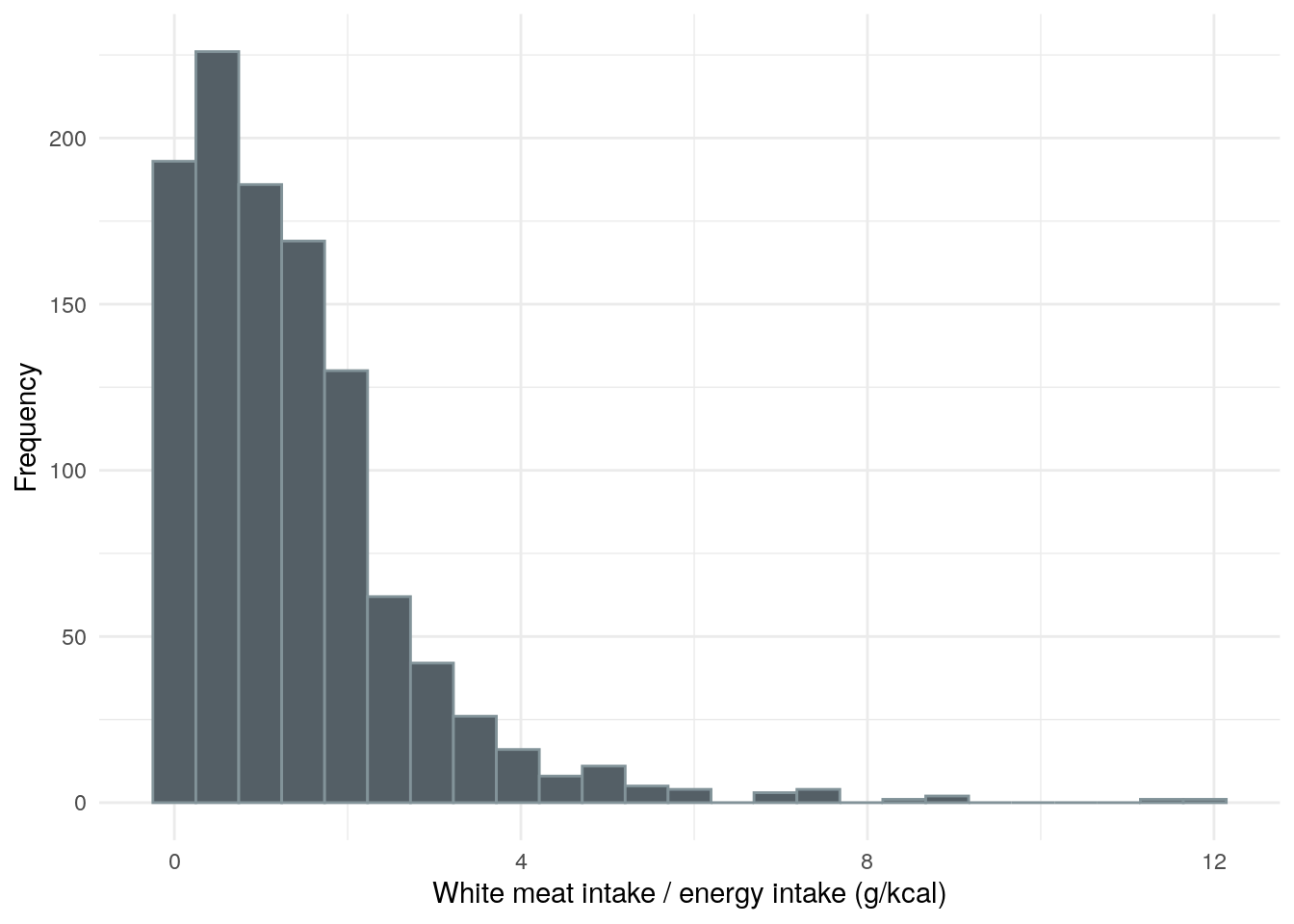
Table 20: ANOVA between white meat intake and FC groups.
Analysis of Variance Model
Df
Sum Sq
Mean Sq
F value
Pr(>F)
cat
2
3.262
1.631
0.8655
0.4212
Residuals
1009
1901
1.884
NA
NA
Code
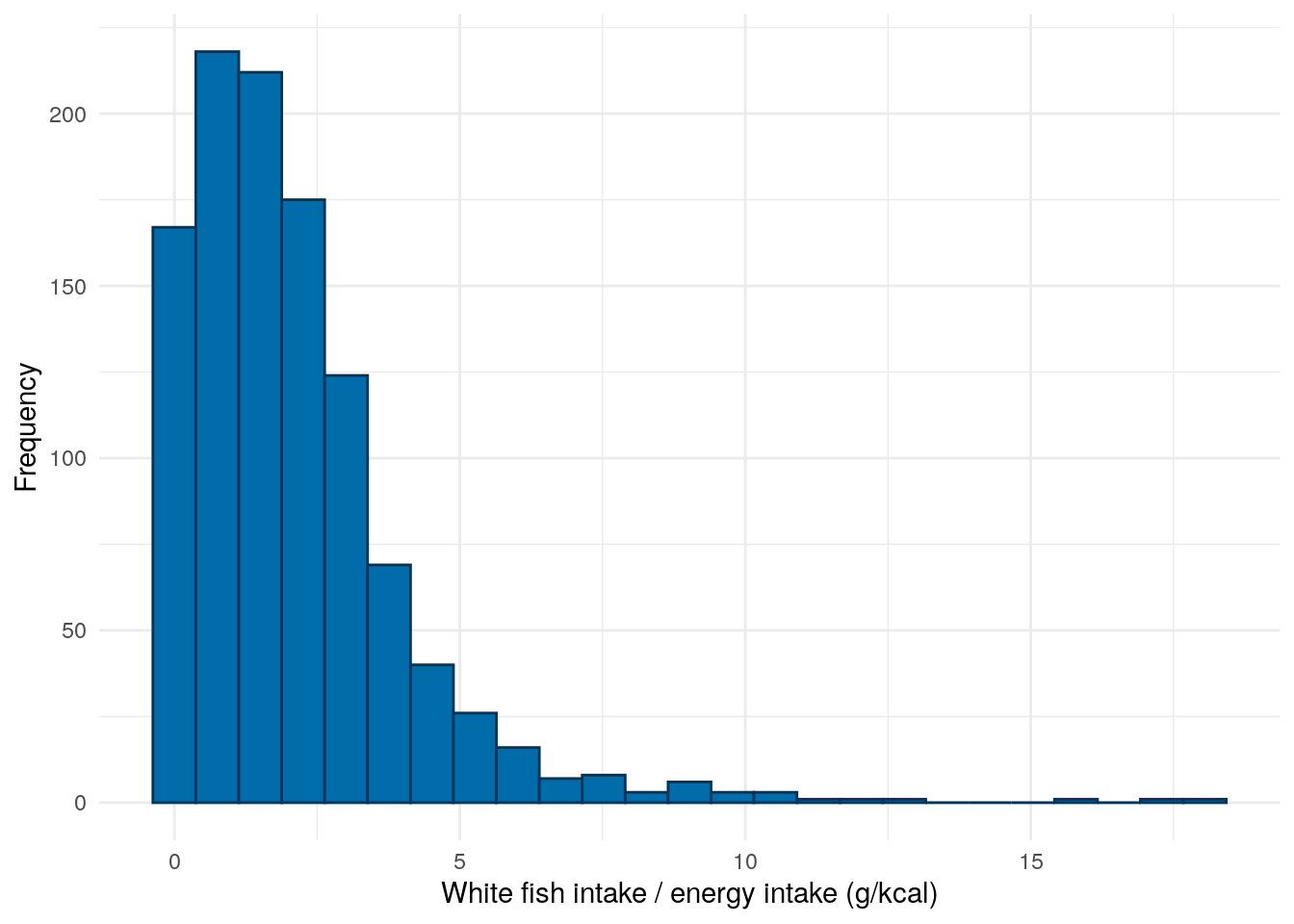
FFQ$whiteFishIntake<-with(FFQ,(WhiteFish+OilyFish)/EnergykCAL)*100demo<-merge(demo,FFQ[, c("ParticipantNo", "whiteFishIntake")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)demo%>%drop_na(whiteFishIntake)%>%ggplot(aes(x =whiteFishIntake))+geom_histogram(bins =25, color ="#003559", fill ="#006DAA")+theme_minimal()+xlab("White fish intake / energy intake (g/kcal)")+ylab("Frequency")
Figure 20: Distribution of white/oily fish intake divided by daily energy intake.
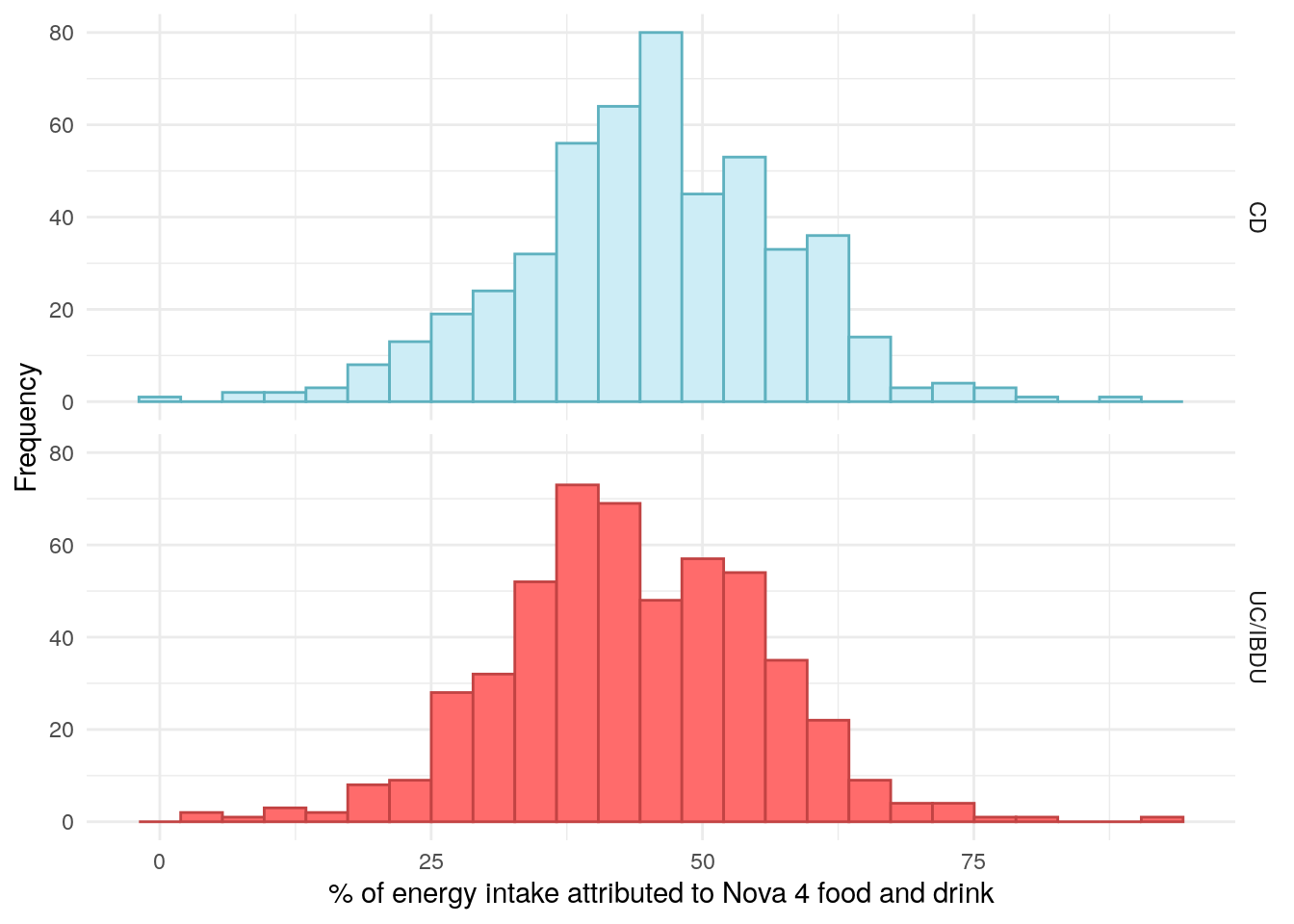
As an alternative to the above analyses, we have also explored the percentage of daily energy intake which is derived from ultra processed (UPF4) groups.
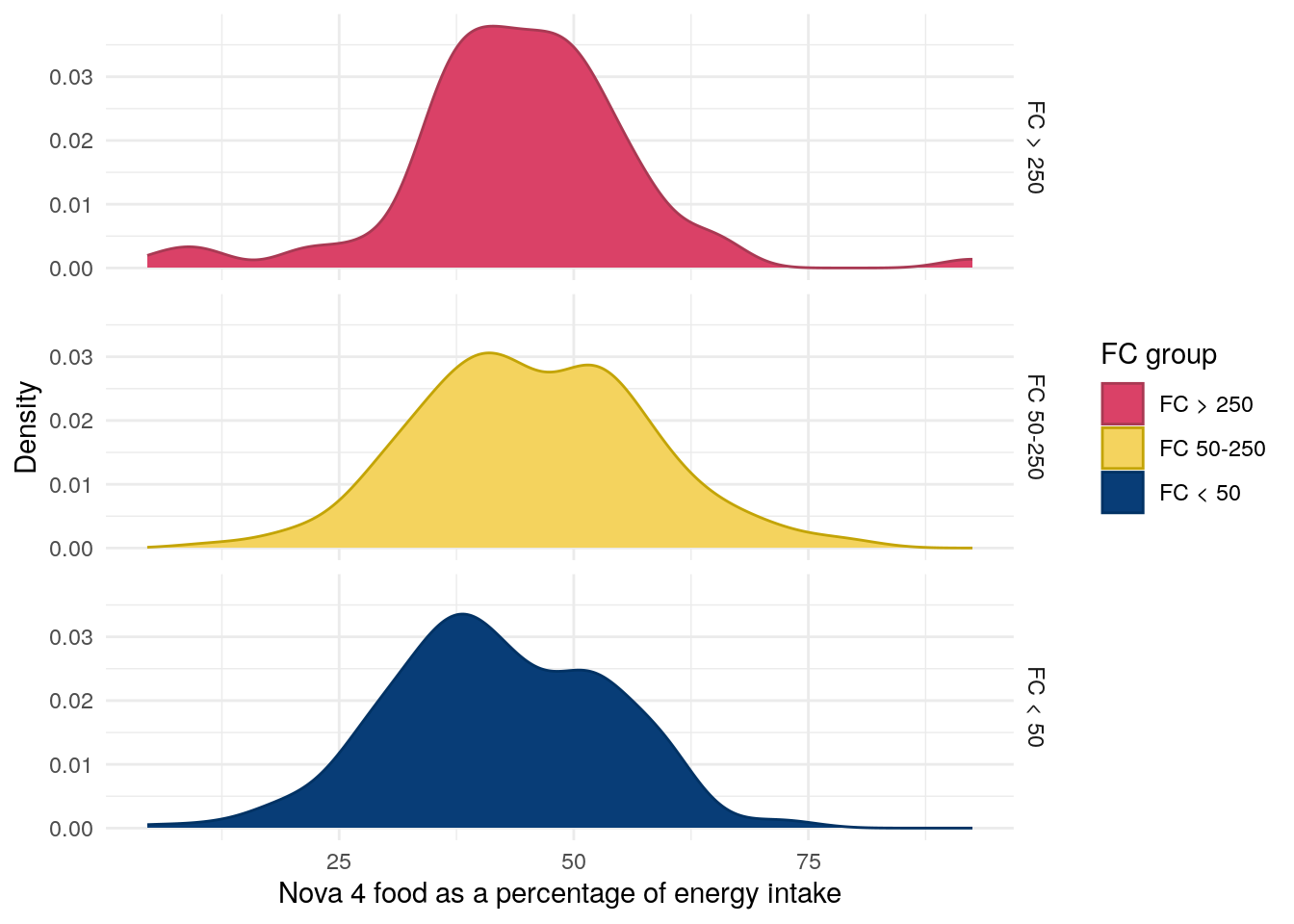
Figure 22: Distribution of Nova 4 food as a percentage of energy intake by FC in UC.
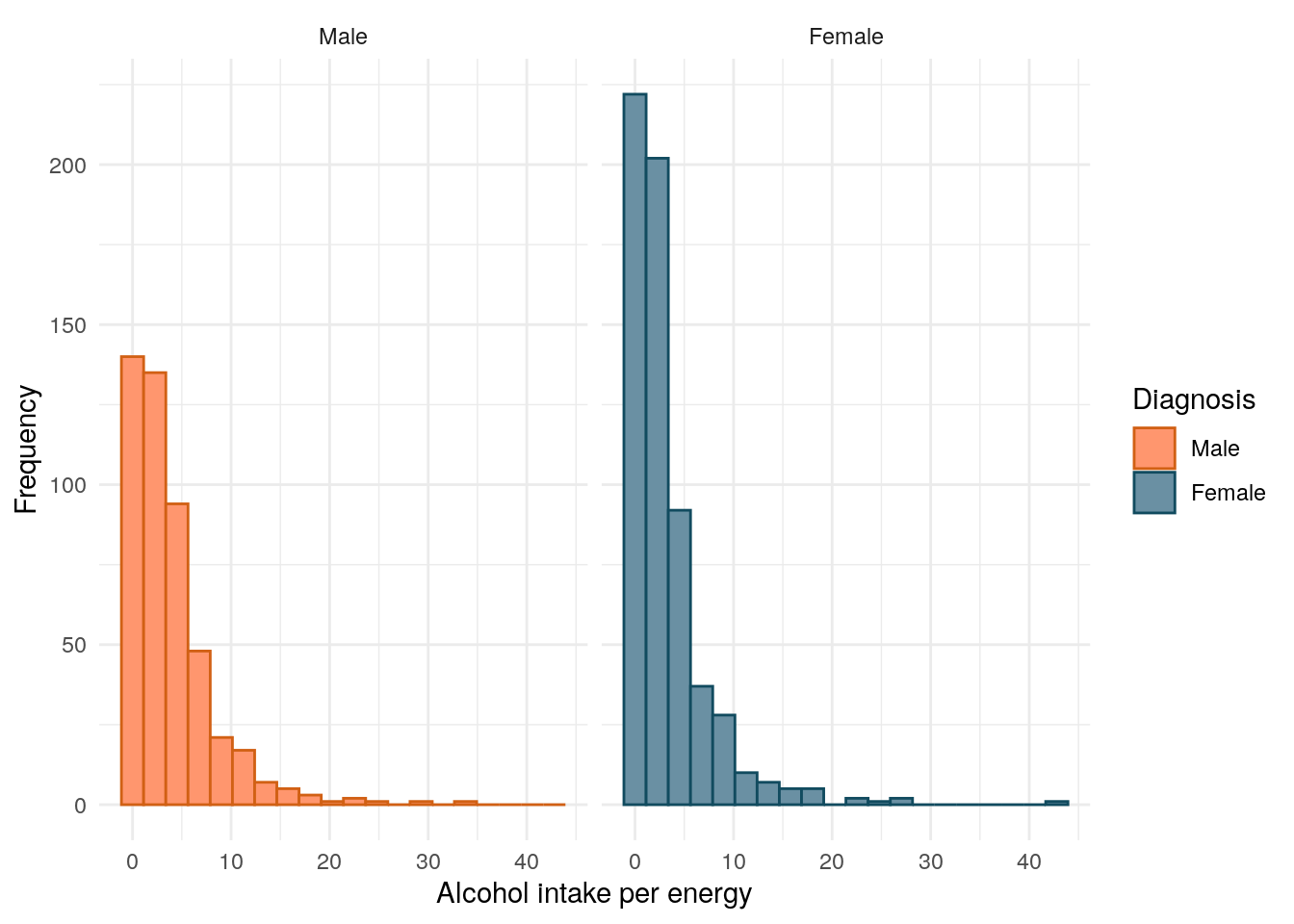
Alcohol use
Code
demo<-FFQ%>%select(ParticipantNo,Alcoholg,Alcohol_percEng,Alcohol_units,Alcohol_units_wk)%>%merge(x =demo, by ="ParticipantNo", all.x =TRUE, all.y =FALSE)demo%<>%mutate( weekly_units_cat =case_when(Alcohol_units_wk<=0.1~"Less than 0.1 units",Alcohol_units_wk>0.1&Alcohol_units_wk<=14~"0.1-14 units",Alcohol_units_wk>14~"More than 14 units"))%>%mutate(weekly_units_cat =factor(weekly_units_cat, levels =c("Less than 0.1 units", "0.1-14 units", "More than 14 units")))
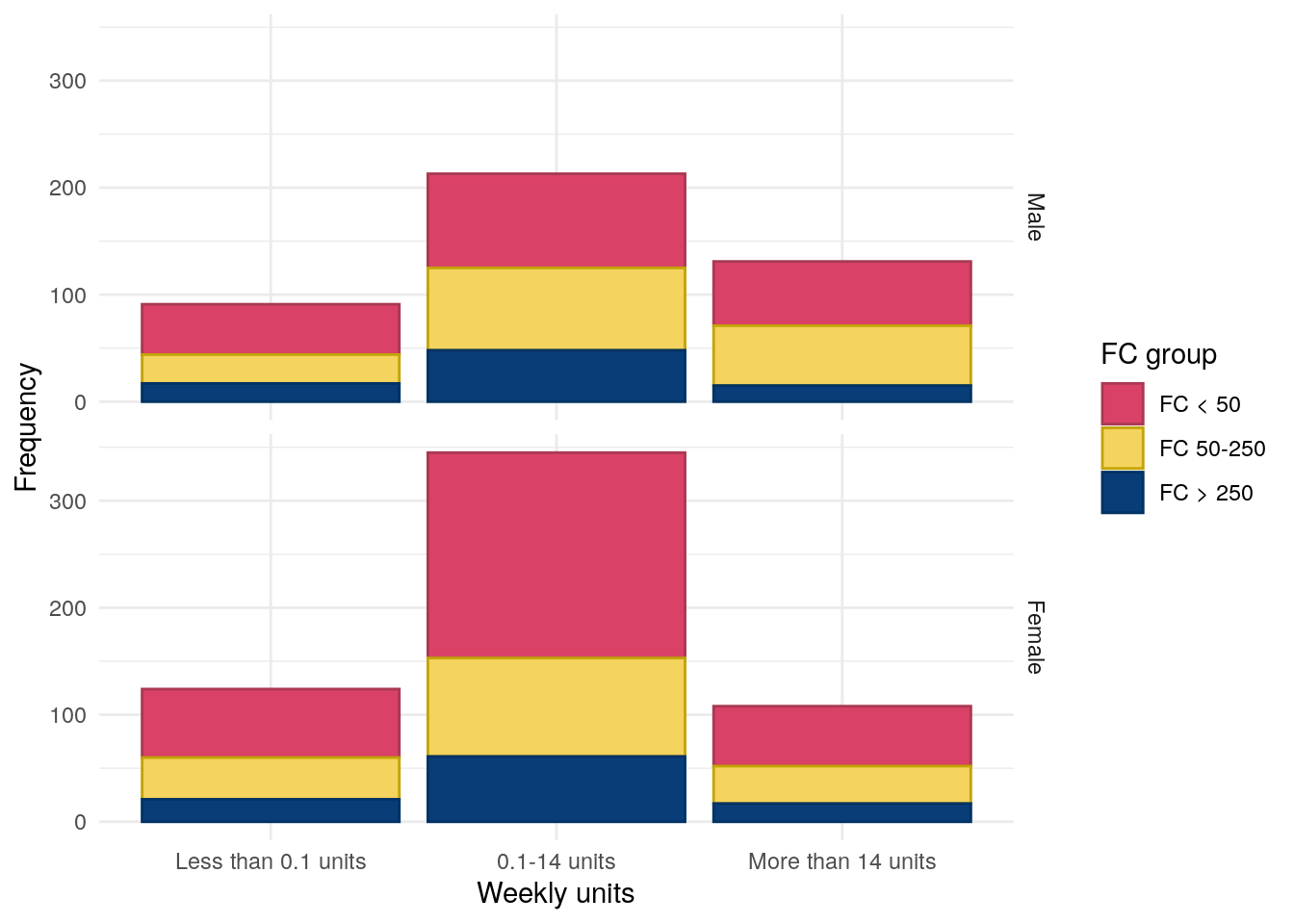
For alcohol usage we consider both alcohol intake as a percentage of energy intake and weekly alcohol units, categorised into 0-0.1, 0.1-14 and more than 14 units per week.
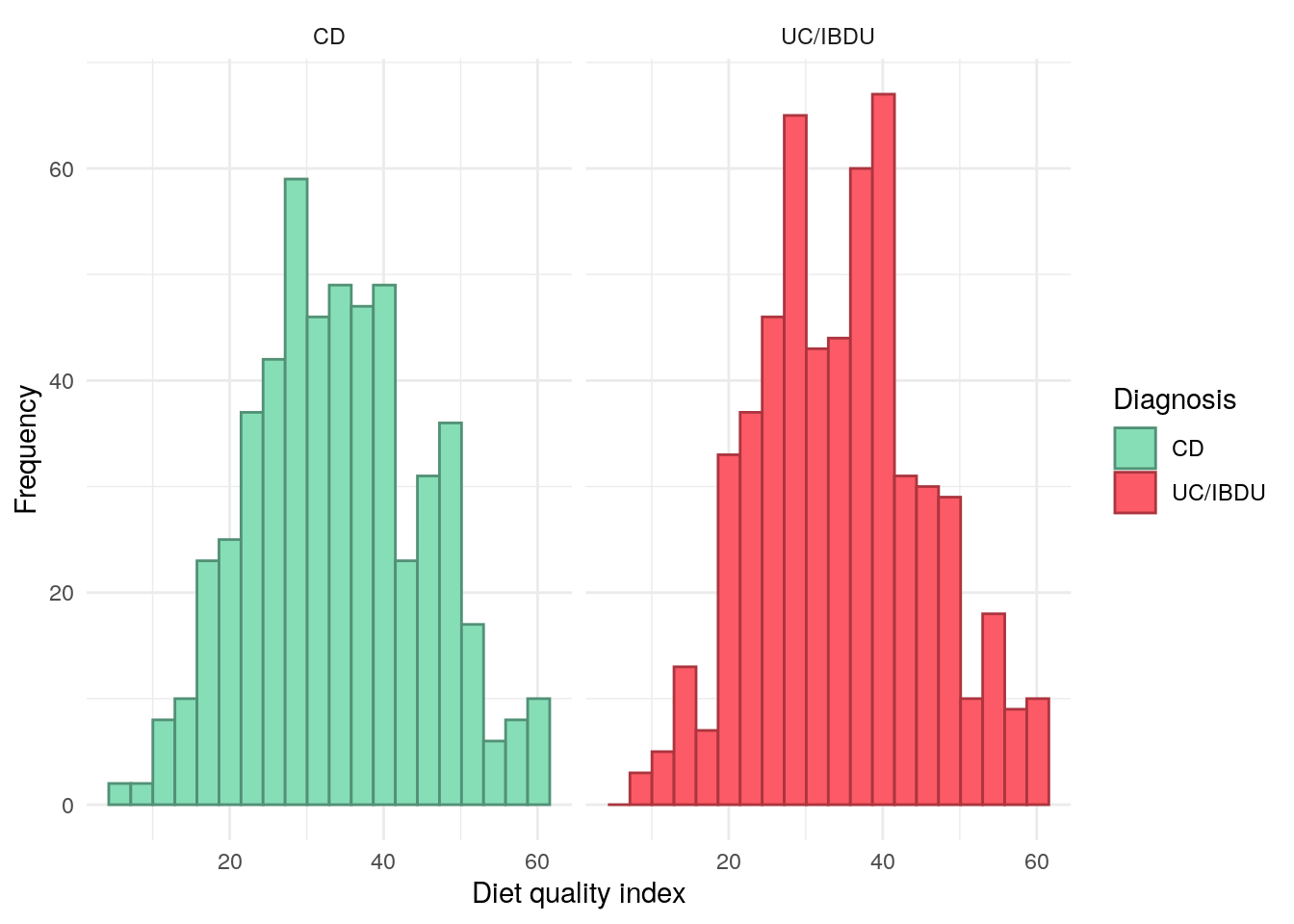
Figure 25: Distribution of diet quality index, stratified by IBD type.
Code
demo%>%drop_na(dqi_tot, cat)%>%pull(dqi_tot)%>%quantile()%>%knitr::kable(digits =2, caption ="Diet quality index quantiles for the FFQ subcohort.", col.names =c("Quantile", "DQI"))
Diet quality index quantiles for the FFQ subcohort.
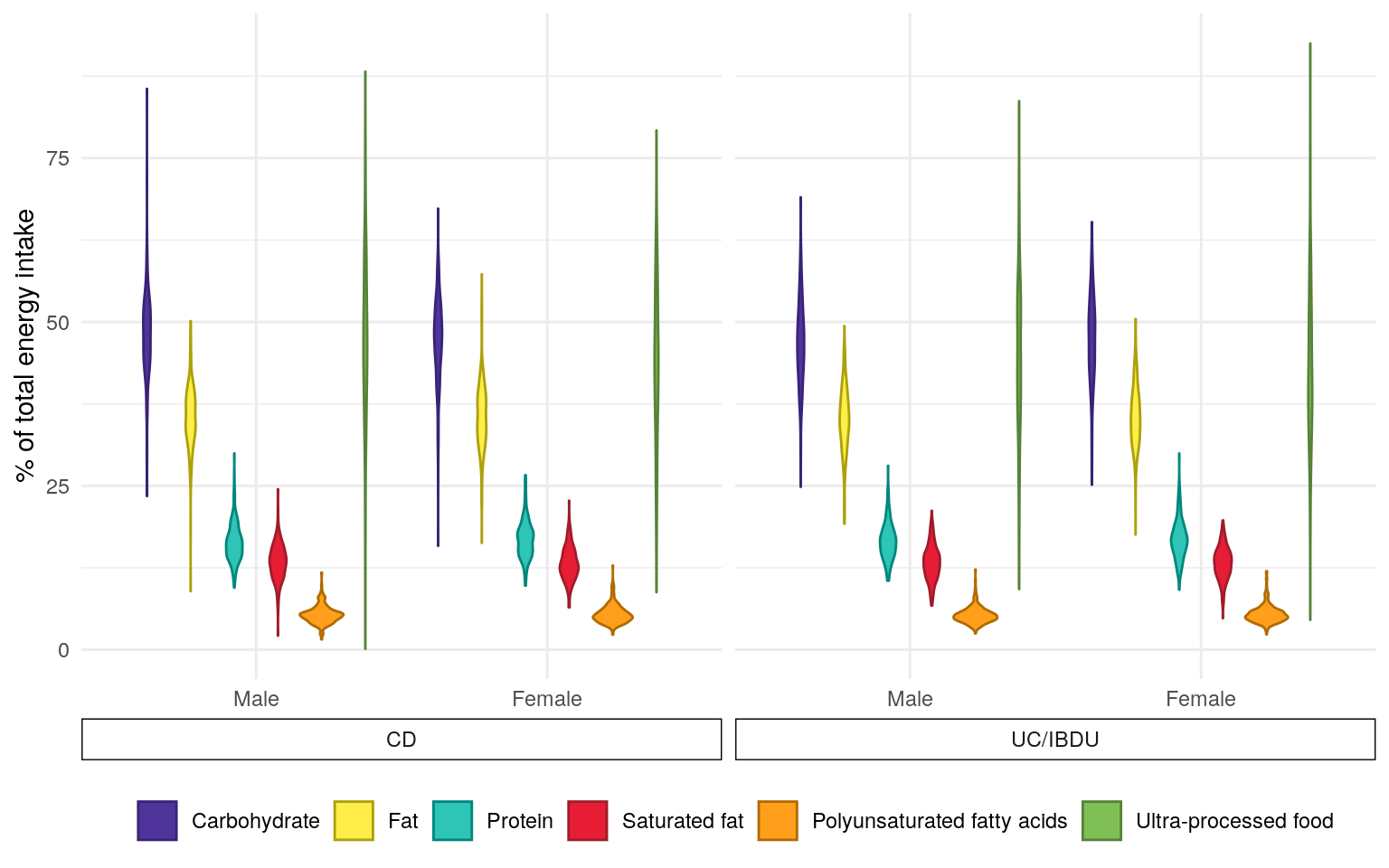
Figure 26 presents macronutrient, PUFA and UPF intake as percentages of total energy intake.
Code
FFQ$Prot_percEng<-((FFQ$Protng*4)/FFQ$EnergykCAL)*100FFQ<-merge(FFQ,nova4[, c("ParticipantNo", "UPF_perc")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)comparison<-reshape2::melt(FFQ, id.vars ="ParticipantNo", measure.vars =c("CHO_percEng","Fat_percEng","Prot_percEng","SatFat_percEng","PUFA_percEng","UPF_perc"))comparison<-merge(comparison,demo[, c("ParticipantNo", "Sex", "diagnosis2")], by ="ParticipantNo", all.x =TRUE, all.y =FALSE)comparison$variable<-factor(comparison$variable, levels =c("CHO_percEng","Fat_percEng","Prot_percEng","SatFat_percEng","PUFA_percEng","UPF_perc"), labels =c("Carbohydrate","Fat","Protein","Saturated fat","Polyunsaturated fatty acids","Ultra-processed food"))p<-ggplot(comparison,aes(color =variable, fill =variable, y =value, x =Sex))+geom_violin()+facet_grid(~diagnosis2, scales ="free_x", space ="free_x", switch ="x")+theme_minimal()+theme( strip.placement ="outside", strip.background =element_rect(fill ="white"), strip.clip ="on", axis.title.x =element_blank(), legend.position ="bottom")+scale_fill_manual( values =c("#4F359B","#FFED49","#2EC4B6","#E71D36","#FF9F1C","#80BF56"))+scale_color_manual( values =c("#392376","#ADA009","#00877C","#9F1C29","#B06B01","#568238"))+labs( y ="% of total energy intake", color ="", fill ="")+guides( colour =guide_legend(nrow =1), fill =guide_legend(nrow =1))ggsave("plots/baseline/diet.png", p, width =12*0.8, height =7*0.8)ggsave("plots/baseline/diet.pdf", p, width =12*0.8, height =7*0.8)p
Figure 26: Dietary distribution of the FFQ subcohort expressed as percentages of energy intake and stratified by sex and diagnosis of either Crohn’s disease or ulcerative colitis/inflammatory bowel disease unclassified.
Ananthakrishnan, Ashwin N., Hamed Khalili, Gauree G. Konijeti, Leslie M. Higuchi, Punyanganie de Silva, Joshua R. Korzenik, Charles S. Fuchs, Walter C. Willett, James M. Richter, and Andrew T. Chan. 2013. “A Prospective Study of Long-Term Intake of Dietary Fiber and Risk of Crohn’s Disease and Ulcerative Colitis.”Gastroenterology 145 (5): 970–77. https://doi.org/10.1053/j.gastro.2013.07.050.
Brotherton, Carol S., Christopher A. Martin, Millie D. Long, Michael D. Kappelman, and Robert S. Sandler. 2016. “Avoidance of Fiber Is Associated with Greater Risk of Crohn’s Disease Flare in a 6-Month Period.”Clinical Gastroenterology and Hepatology 14 (8): 1130–36. https://doi.org/10.1016/j.cgh.2015.12.029.
Cordova, Reynalda, Vivian Viallon, Emma Fontvieille, Laia Peruchet-Noray, Anna Jansana, Karl-Heinz Wagner, Cecilie Kyrø, et al. 2023. “Consumption of Ultra-Processed Foods and Risk of Multimorbidity of Cancer and Cardiometabolic Diseases: A Multinational Cohort Study.”The Lancet Regional Health - Europe 35 (December): 100771. https://doi.org/10.1016/j.lanepe.2023.100771.
Kim, Soowon, Pamela S. Haines, Anna Maria Siega-Riz, and Barry M. Popkin. 2003. “The Diet Quality Index-International (DQI-i) Provides an Effective Tool for Cross-National Comparison of Diet Quality as Illustrated by China and the United States.”The Journal of Nutrition 133 (11): 3476–84. https://doi.org/10.1093/jn/133.11.3476.
Marion-Letellier, Rachel, Guillaume Savoye, Beck Paul L., Remo Panaccione, and Subrata Ghosh. 2013. “Polyunsaturated Fatty Acids in Inflammatory Bowel Diseases: A Reappraisal of Effects and Therapeutic Approaches.”Inflammatory Bowel Diseases 19 (3): 650–61. https://doi.org/10.1097/mib.0b013e3182810122.
Monteiro, Carlos Augusto, Geoffrey Cannon, Jean-Claude Moubarac, Renata Bertazzi Levy, Maria Laura C Louzada, and Patrícia Constante Jaime. 2017. “The UN Decade of Nutrition, the NOVA Food Classification and the Trouble with Ultra-Processing.”Public Health Nutrition 21 (1): 5–17. https://doi.org/10.1017/s1368980017000234.
Narula, Neeraj, Emily C L Wong, Mahshid Dehghan, Andrew Mente, Sumathy Rangarajan, Fernando Lanas, Patricio Lopez-Jaramillo, et al. 2021. “Association of Ultra-Processed Food Intake with Risk of Inflammatory Bowel Disease: Prospective Cohort Study.”BMJ, July, n1554. https://doi.org/10.1136/bmj.n1554.
Source Code
---title: "Diet"author: - name: "Nathan Constantine-Cooke" corresponding: true url: https://scholar.google.com/citations?user=2emHWR0AAAAJ&hl=en&oi=ao affiliations: - ref: IGC - name: "Beatriz Gros" url: https://ibd-eii.com/ affiliations: - ref: Spain - ref: IBD - name: "Maiara Brusco De Freitas" url: "https://scholar.google.com/citations?user=RfXbXL8AAAAJ&hl=en&oi=ao" affiliations: - ref: PREDICTbibliography: Baseline.bib ---## Introduction```{R Setup}set.seed(123)source("Baseline/utils.R")################ Packages ################library(plyr) # Used for mapping valuessuppressPackageStartupMessages(library(tidyverse)) # ggplot2, dplyr, and magrittrlibrary(readxl) # Read in Excel fileslibrary(lubridate) # Handle dateslibrary(datefixR) # Standardise dateslibrary(patchwork) # Arrange ggplots# Generate tablessuppressPackageStartupMessages(library(table1))library(knitr)library(pander)# Generate flowchart of cohort derivationlibrary(DiagrammeR)library(DiagrammeRsvg)# paths to PREdiCCt dataif (file.exists("/docker")) { # If running in docker data.path <- "data/final/20221004/" redcap.path <- "data/final/20231030/" upf.path <- "data/final/20240924/" prefix <- "data/end-of-follow-up/" outdir <- "data/processed/"} else { # Run on OS directly data.path <- "/Volumes/igmm/cvallejo-predicct/predicct/final/20221004/" redcap.path <- "/Volumes/igmm/cvallejo-predicct/predicct/final/20231030/" upf.path <- "/Volumes/igmm/cvallejo-predicct/predicct/final/20240924/" prefix <- "/Volumes/igmm/cvallejo-predicct/predicct/end-of-follow-up/" outdir <- "/Volumes/igmm/cvallejo-predicct/predicct/processed/"}demo <- readRDS(paste0(outdir, "demo-biochem.RDS"))FFQ <- read_xlsx(paste0( prefix, "predicct ffq_nutrientfood groupDQI all foods_data (n1092)Nov2022.xlsx"))FFQ$meat_overall <- rowSums(FFQ[, paste0("meat7", letters[1:12], "_grams")])FFQ$fish_overall <- rowSums(FFQ[, paste0("fish8", letters[1:13], "_grams")])FFQ$ParticipantNo <- FFQ$participantnodemo <- merge(demo, FFQ[, c( "ParticipantNo", "Meat_sum", "meat_overall", "fish_overall", "fibre", "PUFA_percEng", "NOVAScore_cat", "dqi_tot" )], by = "ParticipantNo", all.x = TRUE, all.y = FALSE)cat_theme <- function(gg) { p <- gg + scale_fill_manual(values = c("#DA4167", "#F4D35E", "#083D77")) + scale_color_manual(values = colorspace::darken(c("#DA4167", "#F4D35E", "#083D77"), 0.2) ) + theme_minimal() p}```PREdiCCt has collected data on diet via food frequency questionnaires (FFQs) andfood diaries. This dietary data has been analysed by staff at the[University of Aberdeen](https://www.abdn.ac.uk/), primarily by[Dr Janet Kyle](https://www.abdn.ac.uk/iahs/profiles/j.kyle), [Dr Graham Horgan](https://www.bioss.ac.uk/people/graham), and[Professor Alex Johnstone](https://www.abdn.ac.uk/rowett/research/profiles/alex.johnstone).Whilst data for many dietary variables have been collected, this reportwill focus on the data outlined in the SAP.1. Protein from animal-sources1. Dietary fibre1. Polyunsaturated fatty acids (PUFAs)1. Nova intake scoreThe data for these variables were extracted from the FFQs. As reportedassociations between dietary data and IBD are often specific to a form of IBDrather than IBD as a whole, these data will be presented stratified by diseasetype. ## Protein from meat sources@fig-meat-sum-dist suggests there are relatively few vegetarians in the PREdiCCtcohort. Whilst some extreme values were observed for protein from meat sources,they remain plausible. ```{R}#| label: fig-meat-sum-dist#| fig-cap: "Distribution of protein intake from meat."#| warning: falsedemo %>%drop_na(Meat_sum) %>%ggplot(aes(x = Meat_sum, color = diagnosis2, fill = diagnosis2)) +geom_histogram(bins =25) +theme_minimal() +theme(legend.position ="none") +labs(x ="Protein from meat sources (g)",y ="Frequency",color ="IBD type",fill ="IBD type" ) +scale_fill_manual(labels =c("UC/IBDU", "Crohn's"),values =c("#CDEDF6", "#FF6B6B") ) +scale_color_manual(labels =c("UC/IBDU", "Crohn's"),values =c("#5EB1BF", "#C24343") ) +facet_grid(rows =vars(diagnosis2))```No association was observed between protein intake from meat and FC in either CDor UC.```{R}#| label: tbl-meat-sum-cd#| tbl-cap: "ANOVA between protein intake from meat and FC groups in Crohn's disease."demo %>%filter(diagnosis2 =="CD") %>%aov(formula = Meat_sum ~ cat) %>%summary() %>%pander()``````{R}#| label: tbl-meat-sum-uc#| tbl-cap: "ANOVA between protein intake from meat and FC groups in UC/IBDU."demo %>%filter(diagnosis2 =="UC/IBDU") %>%aov(formula = Meat_sum ~ cat) %>%summary() %>%pander()```## Overall meat intake```{R}#| label: fig-meat-overall-dist#| fig-cap: "Distribution of overall meat intake."#| warning: falsedemo %>%drop_na(meat_overall) %>%ggplot(aes(x = meat_overall, color = diagnosis2, fill = diagnosis2)) +geom_histogram(bins =25) +theme_minimal() +theme(legend.position ="none") +labs(x ="Meat intake (g)",y ="Frequency",color ="IBD type",fill ="IBD type" ) +scale_fill_manual(labels =c("UC/IBDU", "Crohn's"),values =c("#CDEDF6", "#FF6B6B") ) +scale_color_manual(labels =c("UC/IBDU", "Crohn's"),values =c("#5EB1BF", "#C24343") ) +facet_grid(rows =vars(diagnosis2))```No association was observed between meat intake and FC in CD. However, asignificant association was observed between meat intake and FC in UC/IBDU[@tbl-meat-overall-uc].```{R}#| label: tbl-meat-overall-cd#| tbl-cap: "ANOVA between meat intake and FC groups in Crohn's disease."demo %>%filter(diagnosis2 =="CD") %>%aov(formula = meat_overall ~ cat) %>%summary() %>%pander()``````{R}#| label: tbl-meat-overall-uc#| tbl-cap: "ANOVA between meat intake and FC groups in UC/IBDU."demo %>%filter(diagnosis2 =="UC/IBDU") %>%aov(formula = meat_overall ~ cat) %>%summary() %>%pander()``````{R}#| label: fig-meat_overall-FC-dist-uc#| fig-cap: "Distribution of meat intake by FC in UC."p <- demo %>%filter(diagnosis2 =="UC/IBDU") %>%drop_na(cat, meat_overall) %>%mutate(cat =fct_rev(cat)) %>%ggplot(aes(x = meat_overall, fill = cat, color = cat)) +geom_density() +facet_grid(rows =vars(cat)) +labs(x ="Meat intake",y ="Density",fill ="FC group",color ="FC group")cat_theme(p)```## Overall fish intake```{R}#| label: fig-fish-overall-dist#| fig-cap: "Distribution of overall fish intake."#| warning: falsedemo %>%drop_na(fish_overall) %>%ggplot(aes(x = fish_overall, color = diagnosis2, fill = diagnosis2)) +geom_histogram(bins =25) +theme_minimal() +theme(legend.position ="none") +labs(x ="Fish intake (g)",y ="Frequency",color ="IBD type",fill ="IBD type" ) +scale_fill_manual(labels =c("UC/IBDU", "Crohn's"),values =c("#CDEDF6", "#FF6B6B") ) +scale_color_manual(labels =c("UC/IBDU", "Crohn's"),values =c("#5EB1BF", "#C24343") ) +facet_grid(rows =vars(diagnosis2))```No association was observed between meat intake and FC in CD. However, asignificant association was observed between meat intake and FC in UC/IBDU[@tbl-meat-overall-uc].```{R}#| label: tbl-fish-overall-cd#| tbl-cap: "ANOVA between fish intake and FC groups in Crohn's disease."demo %>%filter(diagnosis2 =="CD") %>%aov(formula = fish_overall ~ cat) %>%summary() %>%pander()``````{R}#| label: tbl-fish-overall-uc#| tbl-cap: "ANOVA between fish intake and FC groups in UC/IBDU."demo %>%filter(diagnosis2 =="UC/IBDU") %>%aov(formula = fish_overall ~ cat) %>%summary() %>%pander()```## Dietary fibreFibre has frequently investigated as a potential factor in IBD pathogenesis,particularly in CD. A study of 170,776 women across 26 years found fibreintake, particularly fibre derived from fruits, to be low for incident CDpatients [@ananthakrishnan_2013].A US study of 1,130 CD subjects found CD patients who reported that they did notavoid high-fibre foods were approximately 40\% less likely to have a diseaseflare in a 6-month period than those who avoided high-fibre foods[@brotherton_2016].There is less evidence of a relationship between UC and dietary fibre. There does not appear to be substantial differences in fibre between CD andUC/IBDU PREdiCCt participants. ```{R}#| label: fig-fibre-dist#| fig-cap: "Distribution of dietary fibre."#| warning: falsedemo %>%drop_na(fibre) %>%ggplot(aes(x = fibre, color = diagnosis2, fill = diagnosis2)) +geom_histogram(bins =25) +theme_minimal() +theme(legend.position ="none") +labs(x ="Dietary fibre",y ="Frequency",color ="IBD type",fill ="IBD type" ) +scale_fill_manual(values =c("#CDEDF6", "#FF6B6B") ) +scale_color_manual(values =c("#5EB1BF", "#C24343") ) +facet_grid(rows =vars(diagnosis2))```No association was found between dietary fibre intake and FC. ```{R}#| label: tbl-fibre-cd#| tbl-cap: "ANOVA between dietary fibre and FC groups in Crohn's disease."demo %>%filter(diagnosis2 =="CD") %>%aov(formula = fibre ~ cat) %>%summary() %>%pander()``````{R}#| label: tbl-fibre-uc#| tbl-cap: "ANOVA between dietary fibre and FC groups in UC/IBDU."demo %>%filter(diagnosis2 =="UC/IBDU") %>%aov(formula = fibre ~ cat) %>%summary() %>%pander()```## Polyunsaturated fatty acidsPUFAs exhibit anti-inflammatory properties and there is evidence of arelationship between PUFAs and UC incidence [@Marion_Letellier_2013]. Researchsuggests that a diet with a poor balance of n-3 and n-6 PUFAs, commonly seen in"Western" diets is associated with IBD risk. The PREdiCCt SAP states n-6 PUFAs will be examined. However, the data obtainedfrom the FFQs describes PUFAs as a whole (including n-3 PUFAs).```{R}#| label: fig-pufa-dist#| fig-cap: "Distribution of polyunsaturated fatty acids."#| warning: falsedemo %>%drop_na(cat) %>%ggplot(aes(x = PUFA_percEng, color = diagnosis2, fill = diagnosis2)) +geom_histogram(bins =25) +theme_minimal() +theme(legend.position ="none") +labs(x ="PUFA intake",y ="Frequency",color ="IBD type",fill ="IBD type" ) +scale_fill_manual(values =c("#CDEDF6", "#FF6B6B") ) +scale_color_manual(values =c("#5EB1BF", "#C24343") ) +facet_grid(rows =vars(diagnosis2))```A significant association was not seen between PUFA intake and FC. ```{R}#| label: tbl-pufa-cd#| tbl-cap: "ANOVA between polyunsaturated fatty acids and FC groups in Crohn's disease."demo %>%filter(diagnosis2 =="CD") %>%aov(formula = PUFA_percEng ~ cat) %>%summary() %>%pander()``````{R}#| label: tbl-pufa-uc#| tbl-cap: "ANOVA between polyunsaturated fatty acids and FC groups in UC/IBDU."demo %>%filter(diagnosis2 =="UC/IBDU") %>%aov(formula = PUFA_percEng ~ cat) %>%summary() %>%pander()``````{R}#| label: fig-PUFA_percEng-FC-dist-uc#| fig-cap: "Distribution ofpolyunsaturated fatty acid intake by FC in UC."p <- demo %>%filter(diagnosis2 =="UC/IBDU") %>%drop_na(cat, PUFA_percEng) %>%mutate(cat =fct_rev(cat)) %>%ggplot(aes(x = PUFA_percEng, fill = cat, color = cat)) +geom_density() +facet_grid(rows =vars(cat)) +labs(x ="PUFA intake",y ="Density",fill ="FC group",color ="FC group")cat_theme(p)```## Diet qualiy indexDiet quality index (DQI) is a measure of overall diet quality ranging from 0to 100. A higher DQI indicates a diverse diet likely meeting recommended dailyintakes but reflecting moderation whilst low values indicate the converse. Weused Diet Quality Index-International (DQI-I) which has been validated for usein diverse populations [@Kim_2003]. It should be noted DQI does not necessarilyrelate to ultra-processed food intake. ```{R}demo %>%drop_na(cat) %>%ggplot(aes(x = dqi_tot, color = diagnosis2, fill = diagnosis2)) +geom_histogram(bins =25) +theme_minimal() +theme(legend.position ="none") +labs(x ="Diet quality index",y ="Frequency",color ="IBD type",fill ="IBD type" ) +scale_fill_manual(values =c("#CDEDF6", "#FF6B6B") ) +scale_color_manual(values =c("#5EB1BF", "#C24343") ) +facet_grid(rows =vars(diagnosis2))``````{R}#| label: tbl-dqi-cd#| tbl-cap: "ANOVA between diet quality index and FC groups in Crohn's disease."demo %>%filter(diagnosis2 =="CD") %>%aov(formula = dqi_tot ~ cat) %>%summary() %>%pander()``````{R}#| label: tbl-dqi-uc#| tbl-cap: "ANOVA between diet quality index and FC groups in UC/IBDU."demo %>%filter(diagnosis2 =="UC/IBDU") %>%aov(formula = dqi_tot ~ cat) %>%summary() %>%pander()``````{R}#| label: fig-dqi_tot-FC-dist-uc#| fig-cap: "Distribution of diet quality index by FC in UC."p <- demo %>%filter(diagnosis2 =="UC/IBDU") %>%drop_na(cat, dqi_tot) %>%mutate(cat =fct_rev(cat)) %>%ggplot(aes(x = dqi_tot, fill = cat, color = cat)) +geom_density() +facet_grid(rows =vars(cat)) +labs(x ="Diet quality index",y ="Density",fill ="FC group",color ="FC group")cat_theme(p)```## Nova intake scoreThere has been a great deal of recent research interest in ultra processed food(UPF) and IBD. For example, @Narula_2021 found UPF intake to be positivelyassociated with IBD risk. The Nova score is a popular approach for classifying UPFs [@Monteiro_2017]. Foodis classified as either unprocessed, processed culinary, processed food, orultra-processed via the Nova score. The University of Aberdeen have developed anextension of the Nova score, the Nova intake score, which can be used tocategorise individuals and their diets instead of individual food items.The following definition of the Nova intake score was written by Liam McAdie during a 5th year medical elective in which he worked on the PREdiCCt dietarydata. The formulae have received minor modifications, but otherwise thedefinitions remain unchanged from McAdie's work. ### DefinitionWhen completing the FFQ, participants were asked to report ($a$) portion sizenormally consumed, ($b$) number of times this portion is consumed in one day and($c$) number of days per week food type is consumed. Participant’s daily averageconsumption (in grams) of a food and drink type ($x$) was calculated by:$$x=\frac{c}{7}(a+b)$$Standardised number of portions consumed daily for food and drink type ($y$) wascalculated by dividing consumption ($x$) by the Foods Standard Agency averageUK-portion size ($z$). $$y= \frac{x}{z}$$Nova intake scores ($N$) were calculated by multiplying the number ofstandardised portions consumed ($y$) by their corresponding Nova score ($M$)assigned in the database. This process is repeated for all 169 food and drinktypes and totalled to give one overall Nova intake score. This score is a markerrepresentative of UPF intake.$$N = \sum_{i = 1}^{169} (y_i M_i)$$### ResultsThe distribution of Nova intake score appears to be uniform across the cohort,as such, it seems likely that these data have been mapped to quantiles and areno longer describing Nova Score categories. ```{R}#| label: fig-novas-dist#| fig-cap: "Distribution of Nova intake scores."demo$NOVAScore_cat <-factor(demo$NOVAScore_cat,levels =1:4,labels =c("Unprocessed","Processed culinary","Processed food","Ultra-processed" ))demo %>%drop_na(NOVAScore_cat) %>%ggplot(aes(x = NOVAScore_cat, color = diagnosis2, fill = diagnosis2)) +geom_bar() +theme_minimal() +theme(legend.position ="none") +labs(x ="Nova intake score",y ="Frequency",color ="IBD type",fill ="IBD type" ) +scale_fill_manual(values =c("#CDEDF6", "#FF6B6B") ) +scale_color_manual(values =c("#5EB1BF", "#C24343") ) +facet_grid(rows =vars(diagnosis2))```No significant association was observed between Nova intake scores and FCgroups. ```{R}#| tbl-cap: "Chi-squared test between Nova intake score and FC groups in Crohn's disease."temp <- demo %>%filter(diagnosis2 =="CD")pander(chisq.test(temp$NOVAScore_cat, temp$cat))``````{R}#| tbl-cap: "Chi-squared test between Nova intake score and FC groups in UC/IBDU."temp <- demo %>%filter(diagnosis2 =="UC/IBDU")pander(chisq.test(temp$NOVAScore_cat, temp$cat))```## Processed food subgroupsIn addition to exploring UPF intake as a whole, we also explore UPF intake bysubcategories. This approach is based on the methodology used by @Cordova_2023.The following categories have been identified by Dr Maiara Brusco De Freitasusing FFQ groupings.Animal-based products (processed meat) is the only subgroup considered which wefound to be significantly associated with FC. ::: {.panel-tabset}### Breads and cereals ```{R}#| label: fig-breadIntake#| fig-cap: "Distribution of processed bread and cereal intake divided by daily energy intake."FFQ$breadIntake <-with(FFQ, (bread1a_grams + bread1b_grams + bread1c_grams + bread1d_grams + cereal2a_grams + cereal2b_grams + cereal2c_grams + cereal2d_grams + cereal2e_grams) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "breadIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(breadIntake) %>%ggplot(aes(x = breadIntake)) +geom_histogram(bins =25, color ="#5C738F", fill ="#759EB8") +theme_minimal() +xlab("Processed bread and cereal intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-breadIntake#| tbl-cap: "ANOVA between processed bread/cereal intake and FC groups."pander(summary(aov(breadIntake ~ cat, data = demo)))```### Sweets and desserts/snack foods```{R}#| label: fig-sweetIntake#| fig-cap: "Distribution of Sweet and dessert/snack intake divided by daily energy intake."FFQ$sweetIntake <-with(FFQ, (Puddings13a_grams + Puddings13b_grams + Puddings13c_grams + Puddings13d_grams + Puddings13e_grams + Puddings13f_grams + Puddings13g_grams + Puddings13h_grams + Chocsetc14a_grams + Chocsetc14b_grams + Chocsetc14c_grams + Chocsetc14d_grams + Chocsetc14g_grams + Chocsetc14h_grams + Chocsetc14i_grams + Biscuits15a_grams + Biscuits15b_grams + Biscuits15c_grams + Biscuits15d_grams + Biscuits15e_grams + Biscuits15g_grams + Cakes16a_grams + Cakes16b_grams + Cakes16c_grams + Cakes16d_grams + Cakes16e_grams) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "sweetIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(sweetIntake) %>%ggplot(aes(x = sweetIntake)) +geom_histogram(bins =25, color ="#B25966", fill ="#FFA3AF") +theme_minimal() +xlab("Sweet/dessert/snack intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-sweetintake-uc#| tbl-cap: "ANOVA between sweet/dessert/snack intake intake and FC for UC/IBDU."demo %>%filter(diagnosis2 =="UC/IBDU") %>%aov(formula = sweetIntake ~ cat) %>%summary() %>%pander()``````{R}#| label: tbl-sweetIntake#| tbl-cap: "ANOVA between sweet/dessert/snack intake and FC groups."pander(summary(aov(sweetIntake ~ cat, data = demo)))```### Artificially and sugar-sweetened beverages```{R}#| label: fig-drinkIntake#| fig-cap: "Distribution of artificially and sugar-sweetened drink intake divided by daily energy intake."FFQ$drinkIntake <-with(FFQ, (Beverages18h_grams + Beverages18i_grams + Beverages18j_grams + Beverages18k_grams + Beverages18n_grams + Beverages18o_grams) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "drinkIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(drinkIntake) %>%ggplot(aes(x = drinkIntake)) +geom_histogram(bins =25, color ="#C58500", fill ="#F4AC45") +theme_minimal() +xlab("Artificial/sugar-sweetened beverage intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-drinkIntake#| tbl-cap: "ANOVA between artificial/sugar-sweetened beverage intake and FC groups."pander(summary(aov(sweetIntake ~ cat, data = demo)))```### Animal-based products (processed meat)```{R}#| label: fig-processedMeatIntake#| fig-cap: "Distribution of processed animal-based product intake divided by daily energy intake."FFQ$processedMeatIntake <-with(FFQ, (meat7b_grams + meat7c_grams + meat7g_grams + meat7i_grams + meat7j_grams + meat7k_grams + meat7l_grams + fish8a_grams + fish8e_grams + fish8k_grams) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "processedMeatIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(processedMeatIntake) %>%ggplot(aes(x = processedMeatIntake)) +geom_histogram(bins =25, color ="#BC0019", fill ="#FF4C55") +theme_minimal() +xlab("Processed animal-based product intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-processedMeatIntake#| tbl-cap: "ANOVA between processed meat intake and FC groups."pander(summary(aov(processedMeatIntake ~ cat, data = demo)))```From @fig-processedMeatIntake-FC, it appears subjects with FC<50μg/g atrecruitment were more likely to consume no, or low levels of, processed meat. ```{R}#| label: fig-processedMeatIntake-FC#| fig-cap: "Distribution of processed animal-based product intake, divided by daily energy intake, and stratified by faecal calprotectin category."demo %>%drop_na(processedMeatIntake, cat) %>%ggplot(aes(x = processedMeatIntake)) +geom_histogram(bins =25, color ="#BC0019", fill ="#FF4C55") +theme_minimal() +xlab("Processed animal-based product intake / energy intake (g/kcal)") +ylab("Frequency") +facet_grid(rows =vars(cat))```### Plant-based alternativesAs one would likely expect, consumption of processed plant-based alternatives islow. ```{R}#| label: fig-plantIntake#| fig-cap: "Distribution of processed plant-based alternatives divided by daily energy intake."FFQ$processedPlantIntake <-with(FFQ, (Milk3d_grams + Sav_etc10d_grams + Sav_etc10e_grams + Sav_etc10f_grams) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "processedPlantIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(processedPlantIntake) %>%ggplot(aes(x = processedPlantIntake)) +geom_histogram(bins =25, color ="#069E79", fill ="#08C99B") +theme_minimal() +xlab("Processed plant-based alternative intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-plantIntake#| tbl-cap: "ANOVA between processed plant-based alternatives intake and FC groups."pander(summary(aov(processedPlantIntake ~ cat, data = demo)))```:::## Un-processed/minimally processed food subgroups::: {.panel-tabset}### Fruit```{R}#| label: fig-fruitIntake#| fig-cap: "Distribution of fruit intake divided by daily energy intake."FFQ$fruitIntake <-with(FFQ, (fruit12a_grams + fruit12b_grams + fruit12c_grams + fruit12c_grams + fruit12f_grams + fruit12g_grams + fruit12h_grams + fruit12i_grams + fruit12j_grams) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "fruitIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(fruitIntake) %>%ggplot(aes(x = fruitIntake)) +geom_histogram(bins =25, color ="#C58901", fill ="#FFD639") +theme_minimal() +xlab("Fruit intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-fruitIntake#| tbl-cap: "ANOVA between fruit intake and FC groups."pander(summary(aov(fruitIntake ~ cat, data = demo)))```### Vegetable and legumes```{R}#| label: fig-vegIntake#| fig-cap: "Distribution of vegetable and legume intake divided by daily energy intake."FFQ$vegIntake <-with(FFQ, (Veg11a_grams + Veg11b_grams + Veg11c_grams + Veg11d_grams + Veg11e_grams + Veg11f_grams + Veg11g_grams + Veg11h_grams + Veg11i_grams + Veg11j_grams + Veg11k_grams + Veg11l_grams + Veg11m_grams + Veg11n_grams + Veg11o_grams + Veg11p_grams + Pulses) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "vegIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(vegIntake) %>%ggplot(aes(x = vegIntake)) +geom_histogram(bins =25, color ="#662E9B", fill ="#A57CD9") +theme_minimal() +xlab("Vegetable and legume intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-vegIntake#| tbl-cap: "ANOVA between vegetable/legume intake and FC groups."pander(summary(aov(vegIntake ~ cat, data = demo)))```### Red meat```{R}#| label: fig-redMeatIntake#| fig-cap: "Distribution of red meat intake divided by daily energy intake."FFQ$redMeatIntake <-with(FFQ, (meat7d_grams + meat7e_grams + meat7h_grams) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "redMeatIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(redMeatIntake) %>%ggplot(aes(x = redMeatIntake)) +geom_histogram(bins =25, color ="#93250B", fill ="#F34213") +theme_minimal() +xlab("VRed meat intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-redMeatIntake#| tbl-cap: "ANOVA between red meat intake and FC groups."pander(summary(aov(redMeatIntake ~ cat, data = demo)))```### White meat```{R}#| label: fig-whiteMeatIntake#| fig-cap: "Distribution of white/oily fish intake divided by daily energy intake."FFQ$whiteMeatIntake <-with(FFQ, meat7f_grams / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "whiteMeatIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(whiteMeatIntake) %>%ggplot(aes(x = whiteMeatIntake)) +geom_histogram(bins =25, color ="#829399", fill ="#545F66") +theme_minimal() +xlab("White meat intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-whiteMeatIntake#| tbl-cap: "ANOVA between white meat intake and FC groups."pander(summary(aov(whiteMeatIntake ~ cat, data = demo)))```### Fish (white and oily)```{R}#| label: fig-whiteFishIntake#| fig-cap: "Distribution of white/oily fish intake divided by daily energy intake."FFQ$whiteFishIntake <-with(FFQ, (WhiteFish + OilyFish) / EnergykCAL) *100demo <-merge(demo, FFQ[, c("ParticipantNo", "whiteFishIntake")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %>%drop_na(whiteFishIntake) %>%ggplot(aes(x = whiteFishIntake)) +geom_histogram(bins =25, color ="#003559", fill ="#006DAA") +theme_minimal() +xlab("White fish intake / energy intake (g/kcal)") +ylab("Frequency")``````{R}#| label: tbl-whiteFishIntake#| tbl-cap: "ANOVA between fish (white and oily) intake and FC groups."pander(summary(aov(whiteFishIntake ~ cat, data = demo)))```:::## Percentage of energy intake```{R}nova4 <-read_xlsx(paste0(upf.path, "NOVA4Scores.xlsx"))colnames(nova4)[c(1, 6)] <-c("ParticipantNo", "UPF_perc")demo <-merge(demo, nova4[, c("ParticipantNo", "UPF_perc")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)```As an alternative to the above analyses, we have also explored the percentage ofdaily energy intake which is derived from ultra processed (UPF4) groups. ```{R}#| label: fig-upfperc-dist#| fig-cap: "Distribution of the percentage of daily energy intake sourced from UPF (Nova score 4) food and drink."demo %>%drop_na(cat) %>%ggplot(aes(x = UPF_perc, color = diagnosis2, fill = diagnosis2)) +geom_histogram(bins =25) +theme_minimal() +theme(legend.position ="none") +labs(x ="% of energy intake attributed to Nova 4 food and drink",y ="Frequency",color ="IBD type",fill ="IBD type" ) +scale_fill_manual(values =c("#CDEDF6", "#FF6B6B") ) +scale_color_manual(values =c("#5EB1BF", "#C24343") ) +facet_grid(rows =vars(diagnosis2))``````{R}#| label: tbl-upfperc-cd#| tbl-cap: "ANOVA between Nova 4 food as a percentage of energy intake and FC for Crohn's diseease."demo %>%filter(diagnosis2 =="CD") %>%aov(formula = UPF_perc ~ cat) %>%summary() %>%pander()``````{R}#| label: tbl-upfperc-uc#| tbl-cap: "ANOVA between Nova 4 food as a percentage of energy intake and FC for UC/IBDU."demo %>%filter(diagnosis2 =="UC/IBDU") %>%aov(formula = UPF_perc ~ cat) %>%summary() %>%pander()``````{R}#| label: fig-UPF_perc-FC-dist-uc#| fig-cap: "Distribution of Nova 4 food as a percentage of energy intake by FC in UC."p <- demo %>%filter(diagnosis2 =="UC/IBDU") %>%drop_na(cat, UPF_perc) %>%mutate(cat =fct_rev(cat)) %>%ggplot(aes(x = UPF_perc, fill = cat, color = cat)) +geom_density() +facet_grid(rows =vars(cat)) +labs(x ="Nova 4 food as a percentage of energy intake",y ="Density",fill ="FC group",color ="FC group")cat_theme(p)```## Alcohol use```{R}#| label: fig-alcohol#| fig-cap: "Distribution of alcohol per energy intake, stratified by sex." demo <- FFQ %>%select(ParticipantNo, Alcoholg, Alcohol_percEng, Alcohol_units, Alcohol_units_wk) %>%merge(x = demo,by ="ParticipantNo",all.x =TRUE,all.y =FALSE)demo %<>%mutate(weekly_units_cat =case_when( Alcohol_units_wk <=0.1~"Less than 0.1 units", Alcohol_units_wk >0.1& Alcohol_units_wk <=14~"0.1-14 units", Alcohol_units_wk >14~"More than 14 units" ) ) %>%mutate(weekly_units_cat =factor( weekly_units_cat,levels =c("Less than 0.1 units", "0.1-14 units", "More than 14 units")))```For alcohol usage we consider both alcohol intake as a percentage of energyintake and weekly alcohol units, categorised into 0-0.1, 0.1-14 and more than14 units per week.### Weekly alcohol units```{R}#| label: fig-alcohol-units#| fig-cap: "Distribution of weekly alcohol units, stratified by sex."p <- demo %>%drop_na(weekly_units_cat, cat) %>%ggplot(aes(x = weekly_units_cat, color = cat, fill = cat)) +geom_bar() +facet_grid(rows =vars(Sex)) +labs(x ="Weekly units",y ="Frequency", color ="FC group",fill ="FC group") +theme_minimal()cat_theme(p) ``````{R}#| label: tbl-alcohol-units#| tbl-cap: "Chi-squared test between weekly alcohol units and FC groups."pander(chisq.test(temp$NOVAScore_cat, temp$cat))```### Percentage of energy```{R}#| label: fig-alcohol-perc#| fig-cap: "Distribution of alcohol intake per energy, stratified by sex."demo %>%drop_na(Alcohol_percEng) %>%ggplot(aes(x = Alcohol_percEng, color = Sex, fill = Sex)) +geom_histogram(bins =20) +facet_grid(cols =vars(Sex)) +theme_minimal() +labs(x ="Alcohol intake per energy",y ="Frequency",color ="Diagnosis",fill ="Diagnosis") +scale_fill_manual(values =c("#FF966E", "#6A90A3")) +scale_color_manual(values =c("#D16014", "#114B5F"))``````{R}#| label: tbl-alcohol#| tbl-cap: "ANOVA between alcohol intake and FC groups."pander(summary(aov(Alcohol_percEng ~ cat, data = demo)))```## Diet quality index```{R}#| label: fig-dqi#| fig-cap: "Distribution of diet quality index, stratified by IBD type."demo %>%drop_na(dqi_tot) %>%ggplot(aes(x = dqi_tot, color = diagnosis2, fill = diagnosis2)) +geom_histogram(bins =20) +facet_grid(cols =vars(diagnosis2)) +theme_minimal() +labs(x ="Diet quality index",y ="Frequency",color ="Diagnosis",fill ="Diagnosis") +scale_fill_manual(values =c("#86DEB7", "#FC5A66")) +scale_color_manual(values =c("#529176", "#AC353F"))``````{R}demo %>%drop_na(dqi_tot, cat) %>%pull(dqi_tot) %>%quantile() %>% knitr::kable(digits =2,caption ="Diet quality index quantiles for the FFQ subcohort.",col.names =c("Quantile", "DQI") )``````{R}#| label: tbl-dqi#| tbl-cap: "ANOVA between diet quality index and FC groups."pander(summary(aov(dqi_tot ~ cat, data = demo)))``````{R Save demo file} saveRDS(demo, paste0(outdir, "demo-diet.RDS"))```## Comparison@fig-diet-dist presents macronutrient, PUFA and UPF intake as percentages oftotal energy intake.```{R}#| label: fig-diet-dist#| fig-cap: "Dietary distribution of the FFQ subcohort expressed as percentages of energy intake and stratified by sex and diagnosis of either Crohn’s disease or ulcerative colitis/inflammatory bowel disease unclassified."#| warning: false#| fig-width: 8FFQ$Prot_percEng <- ((FFQ$Protng *4) / FFQ$EnergykCAL) *100FFQ <-merge(FFQ, nova4[, c("ParticipantNo", "UPF_perc")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)comparison <- reshape2::melt(FFQ,id.vars ="ParticipantNo",measure.vars =c("CHO_percEng","Fat_percEng","Prot_percEng","SatFat_percEng","PUFA_percEng","UPF_perc" ))comparison <-merge(comparison, demo[, c("ParticipantNo", "Sex", "diagnosis2")],by ="ParticipantNo",all.x =TRUE,all.y =FALSE)comparison$variable <-factor(comparison$variable,levels =c("CHO_percEng","Fat_percEng","Prot_percEng","SatFat_percEng","PUFA_percEng","UPF_perc" ),labels =c("Carbohydrate","Fat","Protein","Saturated fat","Polyunsaturated fatty acids","Ultra-processed food" ))p <-ggplot( comparison,aes(color = variable, fill = variable, y = value, x = Sex)) +geom_violin() +facet_grid(~diagnosis2,scales ="free_x",space ="free_x",switch ="x" ) +theme_minimal() +theme(strip.placement ="outside",strip.background =element_rect(fill ="white"),strip.clip ="on",axis.title.x =element_blank(),legend.position ="bottom" ) +scale_fill_manual(values =c("#4F359B","#FFED49","#2EC4B6","#E71D36","#FF9F1C","#80BF56" ) ) +scale_color_manual(values =c("#392376","#ADA009","#00877C","#9F1C29","#B06B01","#568238" ) ) +labs(y ="% of total energy intake",color ="",fill ="" ) +guides(colour =guide_legend(nrow =1),fill =guide_legend(nrow =1))ggsave("plots/baseline/diet.png", p, width =12*0.8, height =7*0.8)ggsave("plots/baseline/diet.pdf", p, width =12*0.8, height =7*0.8)p```## Missingness```{R}demo %>%filter(ParticipantNo %in% FFQ$ParticipantNo) %>%select( Meat_sum, meat_overall, fish_overall, fibre, PUFA_percEng, NOVAScore_cat, dqi_tot, breadIntake, sweetIntake, drinkIntake, processedMeatIntake, processedPlantIntake, fruitIntake, vegIntake, redMeatIntake, whiteMeatIntake, whiteFishIntake, UPF_perc, Alcohol_percEng, SiteName ) %>%missing_plot2(title ="Disease phenotyping missingness")```## Reproduction and reproducibility {.appendix}<details class = "appendix"> <summary> Session info </summary>```{R Session info}#| echo: falsepander::pander(sessionInfo())```</details>Licensed by <a href="https://creativecommons.org/licenses/by/4.0/">CC BY</a> unless otherwise stated.